Last updated Sep. 30, 2023 by Benedict Osas

The demand for top ITIL interview questions and answers is increasing due to the need for its rising need for professionals. Even today, thousands of organizations are actively looking for ITIL experts to implement their IT service management better. However, getting a job as an ITIL expert in any company would require you to have the required certification and pass their interview process.
ITIL interviews can be challenging because of the sudden ridiculing question (if not answered correctly) that the interviewer might ask. It is always better to prepare ahead to protect yourself from getting stunned by an interviewer’s question.
Below is a complete list of some of the probable questions you’re most likely to encounter during an ITIL interview, plus the expected solutions. This is the most in-depth article on the ITIL Interview question you will see on the internet today. We have researched and reviewed the questions and answers thoroughly to prepare you for your following interview. We have also included illustrative images to give you a better understanding and grasp of the answers.
Q1: What is ITIL?

This question is one of the fundamental things that the interviewer would most likely ask you at the beginning of the interview. Interviewers generally ask this question to test your basic understanding of ITIL, and how you approach the question in your answer matters a lot.
When posed with this question, you expect to define the concept, its applications, and its benefits to businesses. A good start in answering this question is by providing the whole meaning of the term ITIL.
Before proceeding to the expected answer to this question, it’s essential to note that ITIL is NOT a methodology—a common misconception by some—but rather a framework that businesses can implement.
You can find a sample of the expected answer to this question below:
Expected answer when asked “What is ITIL?” in an interview.
ITIL means Information Technology Infrastructure Library. It is a framework that consists of a set of well-defined practices or guidelines that organizations (of all sizes and types) can adopt for the implementation of their IT activities, such as IT asset management (ITAM) and IT service management (ITSM).
The framework helps businesses align all the stages of their IT services, including selection, planning, delivery, and maintenance, with their goals and objectives. It also allows organizations to establish cost-effective practices, manage business risks, create a stable IT environment, improve customer relationships, and more.
Don’t try to over impress the interviewer by talking about off-point topics like the history of ITIL, the service lifecycle, or processes involved unless being specifically asked otherwise. This behavior can have a boomerang effect and can potentially dampen your chances of acing your interview.
Q2. What is ITSM?
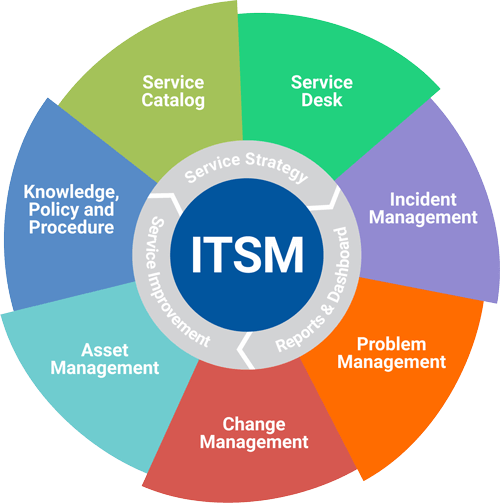
This question is one of the most probable questions you’re likely to come across in an ITIL interview. Most organizations have an IT service management in place whether they are aware or not.
And, the primary purpose of ITIL is to help organizations better implement their ITSM; that’s why it’s primal for the interviewer to ask this question. First, understand that this question aims to probe into your knowledge of ITSM, such as the meaning of the concept, its application and benefits to businesses, the various processes involved, and the frameworks used in implementing ITSM.
Knowing this will help you determine what approach you can give when answering, but at least, the interviewer expects you to explain how ITSM helps run a business. When asked this question in an ITIL interview, below is an excellent approach to answering the question.
Expected answer when asked “What is ITSM?” in an interview.
ITSM stands for Information Technology Service Management. It refers to a systematic process that focuses on helping businesses design, deliver, manage, and improve their IT services to their end-users (customers and employees that utilize the services). It involves the seamless integration of technology, processes, and people to create value.
The various processes involved in ITSM are Problem Management, Incident Management, Knowledge Management, Project Management, Asset Management, and Change Management.
While most organizations adopt the ITIL framework for their ITSM, other well-known frameworks include:
- TOGAF (The Open Group Architecture Framework),
- eTOM (Enhanced Telecom Operations Map),
- MOF (Microsoft Operations Framework),
- ISO 20000
- COBIT (Control Objectives for Information and Related Technologies)
- Six Sigma, etc.
Note that different ITSM frameworks have other purposes and benefits applicable only to specific industries or organizations. It would be best if you had at least a basic understanding of all these frameworks, and discussing why the ITIL framework is best for the company you’re applying for can give you the edge you need to ace the interview.
Q3. What are the benefits of ITIL?
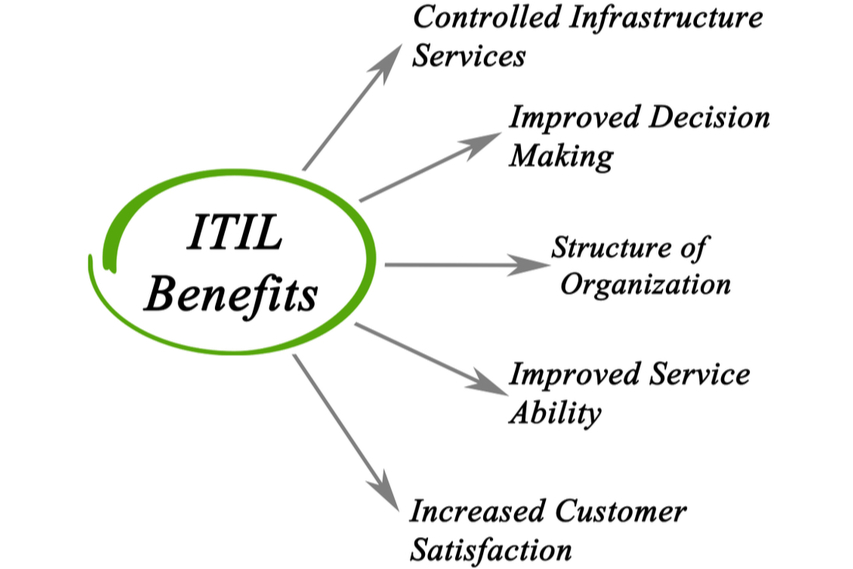
Many ITIL interviewees have pointed out this question as one of the cores questions the interviewer most likely asks you in an ITIL interview. ITIL is the most popular framework for implementing ITSM because many organizations have seen ITIL’s positive impact on their businesses. These benefits are the key reason why many companies are looking for ITIL experts.
Your answer to this question should tell your interviewer “What the company would gain by hiring you to implement their ITIL,” and this should be the core foundation of your response. Correctly answering this question is very important if you want to crack your following interview, and below is an excellent approach to nailing this question.
Expected answer when asked “What are the benefits of ITIL?” in an interview.
Organizations could derive many benefits from adopting ITIL to business, and here are a few of them:
- Integration of IT services into business: ITIL helps organizations to align IT services with their company. The framework encourages enterprises to adopt IT as a core and integral component of business operation. This capability allows businesses to derive optimal value from the services rendered while minimizing inputs.
- Service Management system: The ITIL framework allows third-party service management systems which help to improve the workflow between the different teams in an organization.
- Customer experience: ITIL helps businesses create, sustain, and grow healthy business-customer relationships through optimized customer experience by ensuring that the organization meets customers’ expectations and IT services are readily available and accessible.
- Cost of production: One of the significant purposes of ITIL is to enable organizations to reduce their cost of production through efficient utilization of resources without neglecting the quality of services produced.
- Risk and service disruption management: The framework consists of the effective incident and problem management practices that monitor and intervene whenever there is a disruption or service failure. This management system helps businesses to quickly identify and solve business problems faster and even predict them.
- Stable IT service environment: The different practices included in the ITIL framework give dynamic businesses the capacity to adapt quickly to the constant changes in the business environment without causing any disruption to service while promoting continual improvement of services.
- Transparent costs: Using the detailed metrics and data available on the ITIL framework gives businesses a bird-eye view of IT assets and expenses, which help organizations make better budget and financial decisions.
When posed this question, make sure to answer in a comprehensive way rather than just points. This approach will tell your interviewer that you fully understand how ITIL can benefit the organization and what the company can gain from hiring you as their ITIL professional.
Q4. What are the features of ITIL?
This question is all about what makes ITIL stand out from other different frameworks. You should be able to provide some of the significant shining points and highlights of the ITIL framework. The recent upgrade (ITIL v4) offers additional and better features than the previous version (ITIL v3 or ITIL 2011). When an interviewer is asking for the components of ITIL, answer the question with the newest version (ITIL v4) in mind.
If you encounter this question in an ITIL interview, consider using the below list as a cornerstone for your answer.
Expected answer when asked “What are the features of ITIL?” in an interview.
The ITIL framework has many critical features peculiar from other frameworks used in ITSM, which includes:
- Based on a single language: A common language is a Critical Success Factor when working on a single goal and procedure across organizational boundaries, such as local IT departments, geographical regions, and engaging with different external suppliers. For global IT service management, the ITIL library provides a neutral standard terminology and set of definitions.
- Data integration capabilities: The ITIL framework supports successful IT asset management, endpoint management, server monitoring, and other skills by providing significant data integration capabilities with several sources.
- Deployment flexibility: Regardless of their initial requirements, IT companies benefit from the ability to grow their deployment at any moment, including the ability to move between on-premise and SaaS-based deployments and vice versa as needed. Because of its adaptability, the ITIL framework can scale with the organization and adapt to its changing needs over time.
- Knowledge-centered support: IT businesses that want to prevent individual or departmental information silos and decrease or eliminate the need to produce multiple solutions to known faults and common problems should use ITIL’s knowledge management process.
- Service desk capabilities: By minimizing the number of ad hoc requests and introducing incident tracking, ticket identification, and other sub-processes that increase efficiency and quality of service, the ITIL framework streamlines the incident management and request fulfillment procedures.
- Strong process automation capabilities: The ITIL framework is designed to streamline processes, cut costs, and save time, particularly through automation. IT operators can respond to more tickets, fulfill more requests, contribute to the knowledge base, or focus on more value-added tasks when common or repetitive tasks are automated. Additionally, automating work lowers the chance of human error and assures that the task is done on time.
The features mentioned above are just the tip of the iceberg of the benefits organizations who adopt the ITIL framework can gain. Although organizations can adopt many other frameworks to implement ITSM, ITIL stands out as the most popular and widely adopted ITSM framework. A survey by Forbes Insights shows that over 47% of organizations follow and implement at least some of the practices described in the ITIL framework.
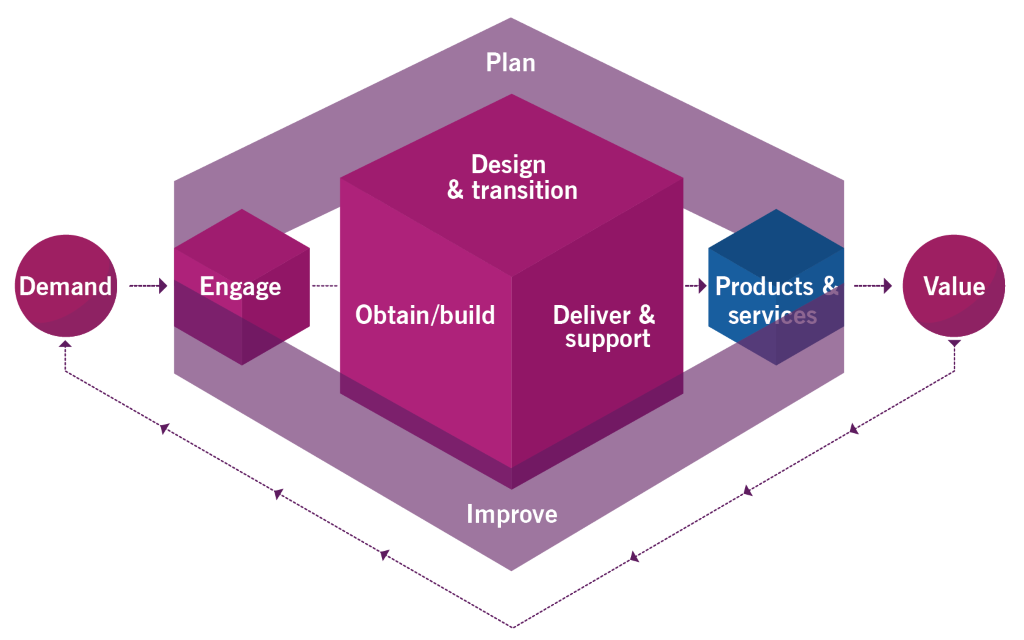
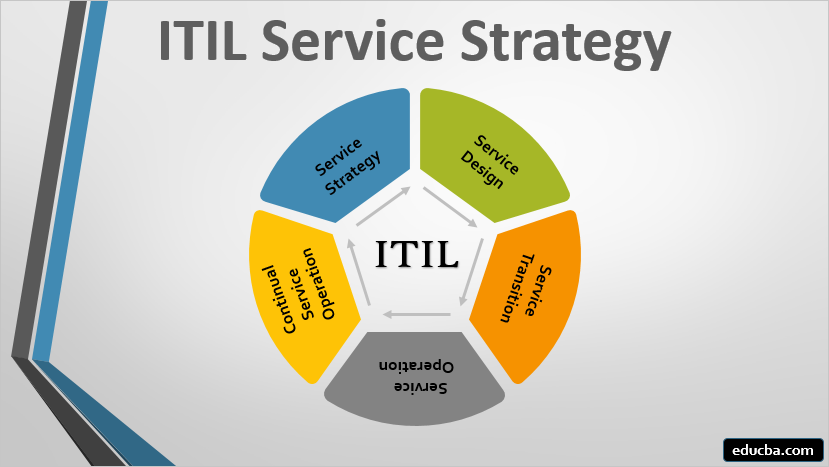
Q5. What are the essential stages of ITIL?
![An Overview of ITIL Concepts and Summary Process [Updated]](https://paypant.com/wp-content/uploads/2022/01/an-overview-of-itil-concepts-and-summary-process-1.jpeg)
This question is about testing your in-depth knowledge of the entire ITIL framework. The interviewer wants to know whether you fully understand all the stages and practices included. This question is one of the essential criteria that interviewers use to determine if you’re fit for the job, so ensure to answer it correctly without mincing words.
Below is an excellent answer to the question above if posed to you in an ITIL interview.
Expected answer when asked “What are the essential stages of ITIL?” in an interview.
There are five essential stages of ITIL:
Service Strategy
This ITIL phase is where a plan for the service lifecycle, including the delivery to the customers, is devised. This stage begins by assessing the marketplace and customers’ needs and helps IT organizations determine which services to offer, identify capabilities that need improvement, and take strategic actions. It also ensures that the strategy/plan aligns with the business’s goals and objectives, allowing the customers to get more value from the services offered.
The different practices included in the lifecycle of the Service Strategy stage are:
- Business Relationship Management
- Demand Management
- Financial Management.
- Service Portfolio Management
- Strategy Management
Service Design
Here is where IT services and additional components get developed before being introduced to a live environment. Already existing services can also be changed or improved during the lifecycle of the Service Design stage. The paramount importance of this stage is to ensure the cost-effective and accurate delivery of service to the right customer and market. The various practices that constitute the lifecycle stage of the Service Design stage include:
- Architecture Management
- Availability Management
- Capacity Management
- Compliance Management
- Design Coordination
- Information Security Management
- IT Service Continuity Management (ITSCM)
- Risk Management
- Service Catalogue Management (SCM)
- Service Level Management (SLM)
- Supplier Management
Service Transition
This stage is where the IT services are built and deployed. The Service Transition stage ensures coordination in how service management processes and changes work. The practices described in the ITIL v4 for implementing the service lifecycle stage of Service Transition includes:
- Application Development
- Change evaluation
- Change Management
- Knowledge Management
- Project Management (Transition Planning and Support)
- Release and Deployment Management
- Service Asset and Configuration Management
- Service Validation and Testing
Service Operations
The Service Operations stage is where organizations deliver IT services to the end-users. This phase ensures that IT services get provided efficiently and effectively, allowing customers to gain more value from the services. Some of the activities during the Service Operation lifecycle include fixing problems, fulfilling user requests, carrying out routine operational tasks, and resolving service failures. The different practices mentioned in the Service Operation book of the ITIL v4 framework are:
- Access Management
- Application Management
- Event Management
- Facilities Management
- Incident Management
- IT Operations Control
- Problem Management
- Request Fulfilment
- Technical Management
Continual Service Improvement
This phase is the last critical stage involved in the ITIL framework. The Continual Service Improvement (CSI) stage focuses on quality management of IT services to ensure continuity of service and quick recovery from service failure. CSI performs quality management by learning from past successes and failures to identify areas where there is a need for improvement.
The primary purpose of CSI is to encourage continual improvement of the quality of IT services and processes as outlined in the ISO 20000 CSI practices. CSI also helps organizations with business analysis focused on business improvement and recovery. The leading practices included in CSI that organizations can employ for service improvement and recovery include:
- Definition of CSI Initiatives
- Monitoring of CSI Initiatives
- Process Evaluation
- Service Review
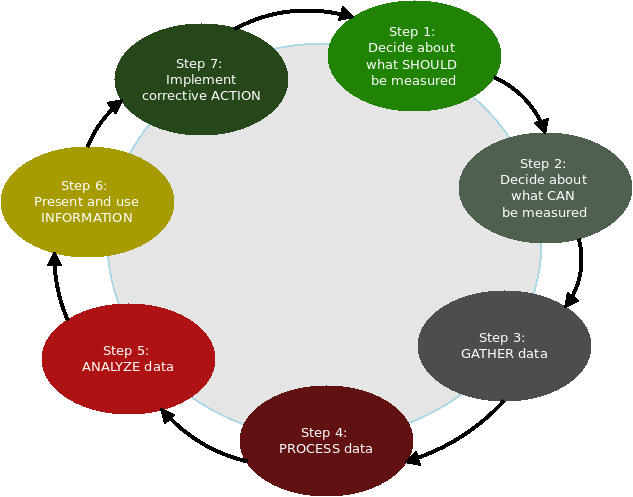
Q6. Mention seven steps involved in continual service improvement.
The main objective of continual service improvement is to help organizations adapt to the consistent changes in a business environment. When asked this question in an interview, make sure not to leave out any details, as companies in dynamic industries would see this as one of the core questions to determine if you’re suitable for the job. Below is a guide and example of the expected answer during an ITIL interview when asked the above question.
In an interview, when asked, “Mention 7 steps involved in continual service improvement” in an interview,” below is the expected answer.
There are different steps or processes involved in the continual service improvement stage. And, these steps are what the interviewer is expecting from you by asking this question. While it’s easy to list out the steps in CSI, explaining how this will happen to the entire service lifecycle would impress the interviewer. The seven (7) steps involved in continual service improvement are:
- Define what you should measure
Organizations should have defined this step in the service strategy and design stages at the beginning of the service life cycle. Which leads CSI to start the process again with the question, ‘Where are we now?’ Now, what should be measured can be identified with both the business and IT in mind.
- Define what you can measure
This step involves different CSI activities to answer the question ‘Where do we want to be?’ The answer would help CSI conduct a gap analysis that would help answer the crucial question ‘How do we get there?’ It would also help identify areas that need improvement.
- Gathering the data
The purpose of this step is to answer the question ‘Did we get there?’ and it usually starts with the collection of data (usually in the Service Operations Stage). Data collection criteria depend on the objectives and goals identified. The data collected is still raw and has not been processed for a conclusion to be made.
- Processing the data
Here is where the CSI processes collected data according to the KPIs and CSFs specifications. This compliance means that CSI would identify the gaps in the data, align inconsistent data, and coordinate the timeframes. This step allows the organization to process data from multiple disparate sources into an ‘apple to apple’ comparison. After achieving consistency in the data collected, we can move to the next step, data analysis.
- Analyzing the data
This step analyses the processed data (information) to expose hidden service gaps, trends, and the impact on business. This step is mainly forgotten or overlooked in many organizations due to having to quickly present data to the management.
- Presenting and using the information
The question this stage is trying to answer is, ‘Did we get there?’ The answer is presented to the various stakeholders and managements to showcase the accurate picture of the feedbacks or results gotten from the improvement efforts. The primary purpose of this stage is to present information to the business in a way that depicts their needs and helps them in determining the next course of action.
- Implementing corrective action
The information received at the end helps to correct, improve, and optimize services. All the previous steps aim to identify problems and find possible solutions. Here, the necessary improvement and corrective measures to improve the service are communicated and explained to the organization.
After completing a CSI lifecycle, the organization now has a new service baseline immediately followed by the initiation of another lifecycle of CSI. And the cycle continuously repeats itself.
Q7. What are the layers of service management measures?
This question is tricky and requires you to understand what it means before attempting to answer it. When asked this question, the interviewer expects you to provide the areas that service management metrics measure.
There are four layers of service management measures which I have explained below.
Expected answer when asked “What are the layers of service management measures?” in an interview.
The four layers of service management measures are:
- Compliance: This measurement ensures that organizations comply with the latest industry process and market standards.
- Effectiveness: This is concerned with the maintenance of the efficacy of the services created.
- Efficiency: This measurement assists with increasing the efficiency of service maintenance and workflow.
- Progress: This measurement is concerned with the progress and improvement of existing service operations.
With the inclusion of service management as one of the processes in the CSI stage under the ITIL framework, organizations now look beyond the physical infrastructure when it comes to IT services delivery.
Q8. How are ICT and BCP related?
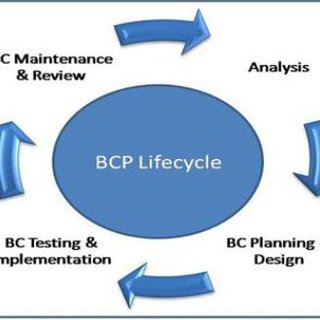
When interviewers ask the question above, it’s usually to test your comprehensive ability. There isn’t much to this question as it looks like but don’t drop your guard; it can give you ‘cold mouth’ in an interview if you’ve not anticipated it.
Before discussing the relationship between ICT and BCP, it’s essential to explain the individual term. Then, you now connect the dot and better understand the relationship between the two. Below is an example of what the interview expects from you.
Expected answer when asked “How are ICT and BCP related?” in an interview.
BCP, or Business Continuity Planning, is an important process in the ITIL framework that helps an organization to create a defensive system capable of preventing and recovering from attacks, threats, or even natural disasters that could have affected the business. The primary purpose of BCP is to ensure the security of personnel and assets, enabling them to function quickly despite a disaster or incident. The process involved in BCP includes:
- IT resilience planning
- IT disaster recovery planning
- IT infrastructure and services (related to data and voice communications)
For BCPs to be effective and efficient, test them continuously to identify weaknesses and correct them after identification. In contrast, Information and Communications Technology or ICT is an extensional term for Information Technology. It refers to the convergence of media technology such as telephone networks and audio-visual with computer networks through unified link or cabling systems.
The sentence below best describes the relationship between BCP and ICT.
“BCP is a systematic process that uses Information and Communication Technology (ICT) to identify, prevent, and even predict threats and attacks to an organization.” A more straightforward way to understand the relationship between ICT and BCP is to think of ICT as the platform or medium used to facilitate the Process of BCP.
Q9. Mention the processes involved in the Design of Services
Another way to view this question is to ask about the processes involved in the ITIL service design stage. It’s not an overstatement to say designing an IT service that reaches customer expectations and meets business needs can be challenging. You’ll need to have a seamless collaboration across all the business units with a straightforward process to manage responsibilities, risks, costs, competing priorities.
The service design stage is the second stage involved in the ITIL framework. It provides best practices and guidelines to govern their services and processes and prepares them for implementation in a live environment. This stage also considers the impact, integration, and implementation of the new service created across the entire service lifecycle.
You can take a cue from to below example when faced with this question in an ITIL interview.
Expected answer when asked “Mention the processes involved in the Design of Services” in an interview.
With a clear understanding of what the question means in mind, below are the processes involved during the Service Design stage.
The processes involved in the design of services are:
- Availability management: The main objective of this process is to ensure that the services delivered meet the users’ and customers’ agreed levels of availability.
- Capacity management: Here, the main focus is on ensuring that the IT resources are sufficient and efficiently used to meet upcoming business requirements
- Design coordination: This process coordinates all service design processes, resources, and activities. The role of design coordination is to ensure the consistency and effectiveness of newly created or improved metrics, processes, technology, architectures, service management information systems, and IT services.
- Information security management: This ITIL process is an ITSM practice that helps organizations protect their data and information from cyber-attacks and data leakage threats. This process would help increase protection against malware and cyber threats, reduce the threat landscape, and keep customer data safe when done correctly.
- IT service continuity management (ITSCM): This Process is an integral part of service design and plays a significant role in the ITIL service delivery. ITSCM is responsible for planning, predicting, preventing, and managing incidents to keep service performance and availability at the maximum level possible, even in a disaster.
- Service catalog management: The role of the service catalog management process is to provide information about all agreed services, usually only to authorized persons. This process also helps an organization to design and maintain a service catalog with accurate, up-to-date information. The owner of this process is called the Service Catalogue Manager.
- Service level management: The main objective of SLM is to ensure that planned and existing IT services meet business targets and requirements.
- Supplier Management: The supplier management process includes all activities involved in improving and managing communication between the organization and third-party vendors that provide services. Supplement management aims to discover and reduce the risk of failure due to lack of supply and maximize value through timely and accurate delivery of services or products to customers.
Q10. What is the significant difference between ITIL v3 and ITIL v4?

Although this question may seem unfair to ITIL v4 professionals who didn’t pass through the ITIL v3 course program, interviewers expect you know the significant difference between the two programs. Understanding how the previous version works can make learning the sequel version easier—a statement made by an ITIL expert on both models.
There are many differences between ITIL v3 and ITIL v4, which shows there had been a lot of improvement done to the former to create the latter. Below is an example of the expected answer the interviewer what from you when they ask this question.
Expected answer when asked “What is the significant difference between ITIL v3 and ITIL v4?” in an interview.
Among the difference between the two versions, the significant ones are:
- ITIL V3 Process vs ITIL V4 Practices: Some of the major highlights of the recent upgrade to ITIL V4 is adopting practices instead of processes as in ITIL V3. There are 26 processes in the ITIL V3 which have been replaced by 34 practices in the ITIL V4 version.
- ITIL V3 Service Lifecycle vs ITIL V4 Service Value System: The ITIL V3 service life cycle is based on a waterfall model that consists of five stages. These stages are Service Continual Service Improvement, Service Design, Service Operations, Service Strategy, and Service Transition. On the other hand, the new version uses a Service Value System which focuses on seamless integration of all activities and components working together as a system to create value.
- ITIL V3 Continual Service Improvement vs ITIL V4 Continual Improvement: Another update present in the new version is the remodeling of the ITIL V3 CSI stage into the CI stage in ITIL V4. The recent version’s continual improvement is in some ways comparable to the previous version’s continual service improvement as both consists of seven steps.
- ITIL V3 9 Guiding Principles vs ITIL V4 7 Guiding Principles: The guiding principle in the ITIL V3 framework are:
- Be Transparent
- Collaborate, and
- Design for Experience
- Focus on Value
- Keep it Simple.
- Observe Directly
- Progress Iteratively
- Start where you are
- Work Holistically
In the ITIL V4 framework, the guiding principles have been reduced to seven (7), including:
- Collaborate and Promote Visibility
- Focus on Value
- Keep it Simple and Practical
- Optimize and Automate
- Progress Iteratively with Feedback
- Start where you are
- Think and Work Holistically
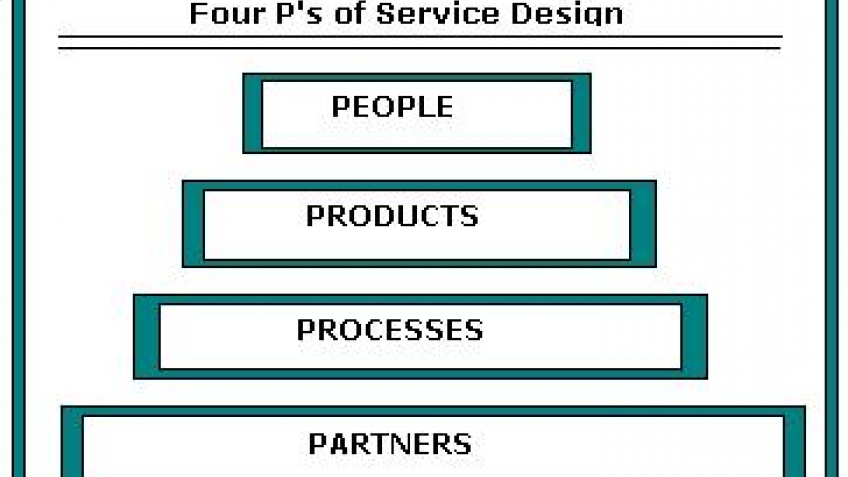
- ITIL V3 Four P’s vs ITIL V4 Four Dimensions:
The four Ps in the ITIL V3 framework are:
- Partners
- People
- process
- Product
The four dimensions in the ITIL V4 framework are:
- Organizations and people
- Information and technology
- Partners and suppliers
- Value streams and processes
Note that the differences between the two versions are not limited to the ones mentioned above. The ones mentioned above are just significant improvements to the previous version; you can further research more differences between the two ITIL versions online.
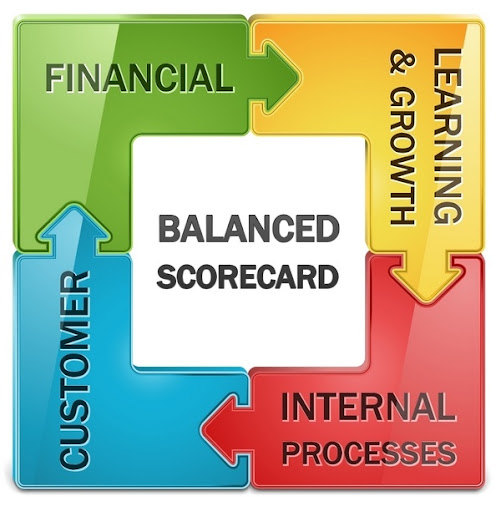
Q11. What is a Balanced Scorecard (BSC)?
This question is as straightforward as it can get. You are only expected to tell the interviewer to want you to know about a balanced scoreboard (BSC). You can approach the question by discussing using a balanced scoreboard in a business and why organizations need to have one. Smartly answering this question would improve your rep in front of the interviewer, giving you a better chance at cracking the interview. Now, how do you answer the above question when asked in an interview?
Expected answer when asked “What is a Balanced Scorecard (BSC)?” in an interview.
A Balanced Scorecard refers to a system that an organization adopting the ITIL v4 framework used to assess the health of the company from four different points of view. Non-profit organizations, governments, and many companies make use of BSC.
The four different perspectives which a balanced scorecard can use to assess an organization’s health are Customer, Financial, Internal, Learning and Growth, and Process.
The purpose of a balanced scorecard is to help businesses better align their strategic objectives with their organizational structure. For effective execution of a plan, companies need to ensure all support functions and business units are aligned.
While you don’t have to elaborate on the balanced scorecard works and the four perspectives more than necessary, if specifically asked by the interviewer, ensure to do so comprehensively.
Q12. What best describes Continual Service Improvement (CSI)?
CSI is one of the five crucial stages of the ITIL framework so that most interviewers would favor this question in an interview. When asked this question, you expect to define the concept in the complete yet concise way possible. You can take a cue from the below-expected answer to the question just to view what is expected from you.
Expected answer when asked “What best describes Continual Service Improvement (CSI)?” in an interview.
In addition to being defined as one of the seven-step improvement steps, CSI refers to applications or techniques companies employ to help locate areas in their IT services they can improve, execute the improvements, and measure the efficiency and efficacy of these efforts over time.
Furthermore, CSI can be best described as applications or techniques that:
- Continually improves the quality and efficiency of IT service to the different end-users.
- Collects feedbacks about offered services and measures the level of customer satisfaction.
- Encourages effective and efficient change management by continually defining the Key Performance Indicators (KPIs).
Don’t explain the concept comprehensively, for example, talking about the processes involved in the continual service improvement stage. What the interviewer expects from you is a concise description of the CSI stage, so don’t bore your interviewer with the extras.
Q13. Define Operational Level Agreement (OLA).
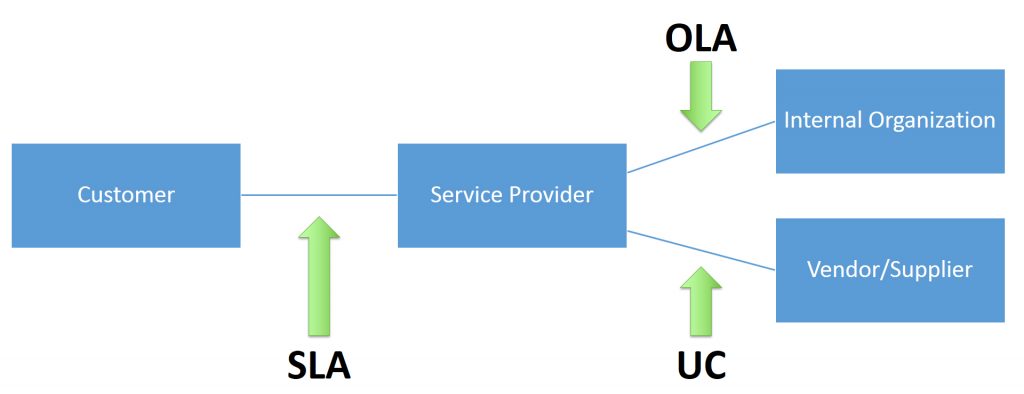
OLAs are an essential part of the ITIL framework, which is why Interviewers would most likely push the question towards you in an interview. However, you shouldn’t just define the term alone; proceed to explain the uses and components of OLAs. The example below should hint at how you answer the question when asked in an interview.
Expected answer when asked “Define Operational Level Agreement (OLA)” in an interview.
Operational Level Agreements or Operating Level Agreements (OLAs) are defined as an agreement or contract—usually between a service provider and any part of the organization that employs its services—that defines their relationship at operational levels. It’s a vital component of the ITIL and ITSM frameworks and can include one or more service targets or objectives. The relationships defined in the OLAs include those between:
- Support Group(s)
- Service Desk
- Operations Management
- Network Management
- Incident Resolution
The OLAs is also used to measure internal service commitments, including the:
- Availability of servers supporting various application
- Response time for incidents or problems assigned to IT groups
Q14. What Is Service Desk?
This question is rumored by previous interviewees who have gone through ITIL interviews at different organizations as being loved by interviewers. And that’s a clear indicator that it’s one of the questions you would want to prepare against.
To get the complete picture of the Service Desk, think of it as the bedrock of all IT service management processes. An excellent response to the question “What is Service Desk?” when asked in an ITIL interview is below.
Expected answer when asked “What is Service Desk?” in an interview.
The service desk serves as a point of contact for different users in the organization to the IT service provider. The responsibility of the service desk is to act whenever there is a disruption in service or incident. Service desk services are managed by administrators using ticketing solutions and help desk. There are four standpoints for implementing Service Desk according to the ITIL v4 framework, they are:
- Organizations and people: Describe the personnel or IT team that create and implement changes, and design and deploy the services and processes in an organization.
- Information and Technology: Serves as the support system for the service desk.
- Value streams and processes: Utilizes procedures and workflows in handling service requests and managing incidents or service disruptions.
- Partners and suppliers: This is the last dimension of the service desk. It involves outsourcing the service desk process to a third-party organization.
Although there are many similarities between the Service Desk and the Help Desk, they do not always mean the same thing. And, something interviewer might want to test your knowledge on both, which is why you should make an effort to know the differences between the two.
Q15. Can IT be applied within the company to other processes?
![Guide to Business Process Design & Analysis [With Examples]](https://paypant.com/wp-content/uploads/2022/01/guide-to-business-process-design-andamp-analysis-w-1.png)
Whether IT can be applied to other processes with an organization is very popular with the interviewer in ITIL interviews. To crack this question, knowledge of the Process that IT can use within a company is essential. The best answer to this question in an ITIL interview has been discussed below.
Expected answer when asked, “Can IT be applied within the company to other processes?” in an interview.
All the processes that IT can be applied to within an organization have been well-defined in the IT impact business processes. The level of adoption now depends on the organization’s needs and requirements. The operations where IT can be applied within a company include:
Following a successful implementation of IT to crucial business processes, many organizations (for example, pharmaceutical companies) have taken the initiative to the extent of the application of IT to their business processes towards critical areas like manufacturing lines and maintenance operations.
Q16. What are the ITIL processes according to the v4 edition?
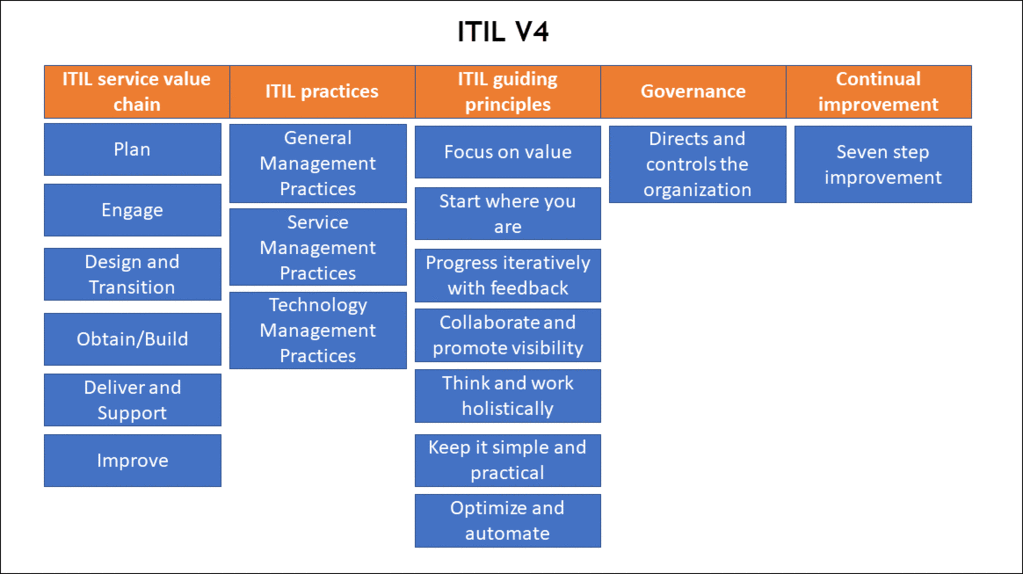
The new update to the ITIL framework is a step forward regarding the processes involved from the previous version. The organization you plan to work for would require you’re up-to-date on the methods in the v4 version, and this question allows the interviewer to assess that. The list of the functions under the ITIL v4 edition is given below.
In an interview, the expected answer when asked, “What are the ITIL processes according to the v4 edition?”
The recent version, ITIL v4 edition, comes with 26 processes under five different service lifecycle stages. The processes within the framework arranged according to the service lifecycle stage includes the following:
Continual Service Improvement
- Seven steps improvement
Service Design
- Availability management
- Capacity management
- Design management
- Information security management
- IT service continuity
- Service catalog management
- Service level management
- Supplier management
Service Operations
- Access management
- Event management
- Incident management
- Problem management
- Service level management
- Service request fulfillment
Service Strategy
- Business relationship management
- Demand management
- Financial management
- Service portfolio management
- Strategy management
Service Transition
- Change evaluation
- Change management
- Knowledge management
- Release and deployment management
- Service assets and configuration management
- Service validation and testing
- Transition planning and support
Q17. Who decides the categorization of a proposed change within an ITIL compliant Change Management process?

This question is one of the indirect questions the interviewer would throw at you to farce you, and if you’re not careful, it can catch you unaware. This is one of the reasons why with ITIL, you should prioritize deep understanding of the concept rather than cramming and memorizing. While the most straightforward response to the question is a Change Manager, you are expected to extend your response beyond just that. You can take a cue from the below example.
Expected answer when asked “Who decides the categorization of a proposed change within an ITIL compliant Change Management process?” in an interview.

The person responsible for making decisions regarding the categorization of a proposed change within an ITIL compliant change management process is a Change Manager.
A change manager is an authorized person responsible for ensuring that the objectives of change initiatives (projects) are completed within budget and time frame, usually by increasing the employees’ number and usage. The change manager is involved in the people side of change, such as job roles and organization structures, systems and technology, and changes to business processes.
The change manager is responsible for creating and implementing change management plans that promote an increase in employee adoption and usage while considering the impact/resistance it would have on the organization. The benefits that an organization derives from the actions of a change manager include benefit realization, value creation, increased, and so on.
While a change manager does not carry out supervisory duties, change management requires a close working relationship with other employees in the organization to be able to work effectively.
Q18. What is SLA?

SLAs are an essential documented agreement used in the ITIL framework, which is why interviewers would want to test your knowledge in this area. When asked this question in an interview, you should define what it is and the stages of ITIL SLAs are being utilized. Below is a sample of what the interview expects from you when they ask this question in an interview.
Expected answer when asked, “What is SLA?” in an interview.
SLAs in ITIL define a form of documented contract agreement involving a customer and the service provider that clearly defines the clients’ expectations and requirements of the services provided. Here, both the customer and service provider can agree on what to expect from the contracted service.
In the ITIL v4 framework, SLAs are usually defined and modified in two critical stages of the ITIL service lifecycle. This includes:
- Continual Service Improvement, and
- Service Design
This makes it important for an organization to always create SLAs alongside the specifications for new or updated services. Also, the SLAs should be reviewed frequently to identify areas that need modification after creating or updating the service. This ensures that the SLA is fair, enforceable, and realistic.
Q19. Name the three types of SLAs?

This question is straightforward to understand. Here, the interviewer wants you to list the three types of service level agreements used in the ITIL framework. But, don’t restrict your answer to list the types; go further to explain the different types of SLAs. This will make you look good in front of the interviewer, see an example of the expected answer below.
Expected answer when asked “Name the three types of SLAs?” in an interview.
There are three types of SLAs highlighted in the ITIL v4 framework. They include: Service-based, Customer-based, and Multi-level or Hierarchical SLAs. To choose the right SLA structure for an organization, company you consider various factors which can determine how efficient the SLA would be. Some of these factors include:
- Corporate Level: This is the same throughout the entire organization and covers all the general issues specific to the organization. Using a security SLA at the organization level as an example, employees must create 8-characters long passwords, which they must change every 30 days. Or, it may be necessary to have an access card with an imprinted photograph for entry.
- Customer Level: All issues relevant to a customer can be covered. Here, the security requirement varies among the departments within the organization. The financial department, for example, would require more full security measures due to the sensitivity of their role, which involves handling the organization’s financial resources.
- Service Level: Covers all issues relevant to a specific service—concerning the customer. It applies only to all customers that use the same service, for example, providing IT support services for customers using the same IP telephony provider.
The multi-level or hierarchical structure is the best for large organizations as it prevents the duplication of effort while allowing customization of services for customers. This means companies can adopt corporate-level SLAs, which cover every department and everyone in the organization, customer-level SLAs only applicable to the department, etc.
Q20. What two Service Management processes will most likely use a management methodology and risk analysis?
 This is another tricky question you are most likely to encounter in an ITIL interview, but it’s as simple as it can be once you understand the question. Since it’s an indirect question, many people get stuck trying to decipher the question, which is why you should prepare ahead for these types of questions. An example of what is expected from you by the interviewer is given below.
This is another tricky question you are most likely to encounter in an ITIL interview, but it’s as simple as it can be once you understand the question. Since it’s an indirect question, many people get stuck trying to decipher the question, which is why you should prepare ahead for these types of questions. An example of what is expected from you by the interviewer is given below.
Expected answer when asked “What two Service Management processes will most likely use a management methodology and risk analysis?” in an interview.
Risk analysis and Management methodology are two important sub-processes that are vital parts of both the IT Service Continuity Management and Availability Management process.
Availability Management
Availability Management is one of the essential processes involved in ITIL Service Design. This process helps an organization to deliver the agreed levels of availability of their services to their users and customers. Availability management was created to compliment other functions such as incident and problem, release and deployment, change and configuration, and architecture management. It helps an organization effectively design, deploy, and manage the security, continuity, and capacity of the entire lifecycle of the created services, including its components and infrastructure.
Organizations can monitor and measure their service availability from two points of view; one from the customer’s point of view through usage patterns and complaints and from the component point of view through alerts and events. The two metrics that organizations can use to determine the degree of success of the availability management process at the service level include:
- Mean time to restore service (MTRS): This indicates the amount of time (measured in hours) that an organization takes before resolving a non-availability of the service incident.
- Mean time between failures (MTBF): This metric shows how frequently service is not available in an organization.
IT service continuity management
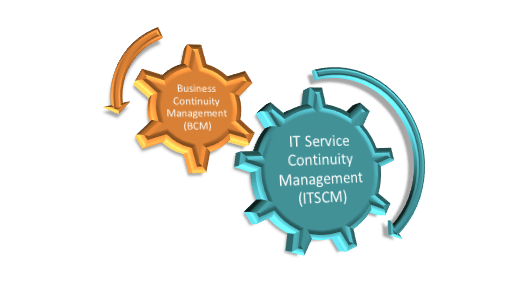
ITSCM is an integral part of the ITIL service delivery process. The primary purpose of ITSCM is to provide organizations with incident prevention, prediction, and management plan to help them maintain the highest possible level of service availability and performance even in the event of a disaster-level incident or service disruption.
Organizations aim to achieve with ITSCM to reduce the impact on business, including downtime and costs following an incident, by putting in place an effective standardized process for service recovery in case the inevitable does occur.
Without a plan for service continuity, the incident recovery process might be delayed or stopped for several reasons. Take a scenario, for example, an incident occurring just two hours past midnight; calling your expert at that time would put you on-call with someone with tired eyes and a foggy state of mind.
Also, what if your expert has lost touch with the code because they’ve had their hands on another project that has been ongoing for weeks or months. Or they might be the newest member of the disaster recovery team, without as much experience resolving issues. This may cause them to panic in the face of a disaster-level incident.
ITSCM, when done correctly, will help alleviate all the delays that could have been caused by disaster panic, time away from the code, midnight alerts, or learning curves.
In addition, it’s worthwhile noting that the IT service continuity management process in the ITIL v4 framework was incorporated to serve as a support for the business continuity management process. This helps organizations to ensure service continuity within the agreed-upon business timelines following a disaster-level service disruption or incident.
Q21. What are the different Knowledge Management Systems (KMS)?

Organizations can make crucial decisions about their entire service process using knowledge management systems. These systems provide them with the means of controlling and managing how information flows throughout their network.
They are also vital towards an accurate, reliable, and trustworthy distribution of knowledge to employees. Interviewers favor this question because it tests your knowledge about the different KMSes used in the ITIL framework. Below is an excellent approach to answering the question when asked in an ITIL interview.
Expected answer when asked “What are the different Knowledge Management Systems (KMS)?” in an interview.
The Knowledge Management Systems are:
- Service Knowledge Management System (SKMS): The Service Knowledge Management System is the IT organization’s principal repository for data, information, and knowledge needed to manage the lifetime of its services. The SKMS is usually not made up of a single system but rather a collection of distinct systems and data sources. The fundamental goal of ITIL SKMS is to store, analyze, and show the data, information, and expertise of the service provider systematically.
- Definitive Media Library (DML): A Definitive Media Library, according to ITIL, is a location where official versions of all media, such as software, documentation, and licenses, are stored.
- Configuration Management Database (CMDB): Organizations make use of the CMDB to store and monitor configuration records along with their relationships throughout their lifecycle. To put it another way, your CMDB maintains data about the configuration of assets within an organization, such as hardware, software, systems, facilities, and occasionally individuals.
- Known Error Database (KEDB): This database contains data that describes the various incidents or conditions in an organization’s IT systems that can potentially lead to a future problem for the users and customers.
- Availability Management Information System (AMIS): The Availability Management Information System is a virtual repository for all Availability Management data, which is typically maintained in several physical places.
- Capacity Management Information System (CMIS): ITIL defines a Capacity Management Information System as a repository for all capacity management data. It could be a virtual repository, with data kept in a variety of physical places.
Q22. What is the relationship between availability, availability service time, and downtime?
This question is designed to test your understanding of availability management. There is nothing fancy about this question, and it only requires an in-depth knowledge of the basic concept of availability to connect the dots. You can see the relationship between the three terms below.
Expected answer when asked, “What is the relationship between availability, availability service time, and downtime?” in an interview.
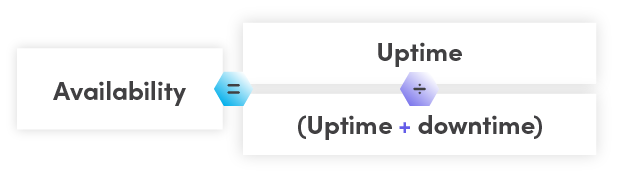
- Availability: This is the ability of an IT service or configuration item to perform its agreed function when needed. It is measured as the percentage of time the configuration item or service would be available. The concept uses past reports to predict the future progression of a service. It helps you determine how well the service will perform over the measurement period.
- Agreed service time: This refers to the standard time the service is expected to be in operation. For example, if it’s indicated in your service level agreement that users are expected to have access to an ERP system from 8:00 AM to 6:00 PM on workdays, then your agreed service time would be 10 hours/600 minutes/36,000 seconds per workday.
- Downtime: This refers to the amount of time during the service’s agreed time when the service is unavailable.
The relationship between the three can be best described using the below equation:
Availability (%) = (Available service time – downtime) / Available service time
Q23. What is the Plan-Do-Check-Act (PDCA) cycle?
The PDCA cycle is an integral part of the continual service improvement stage. The cycle maps out how the entire lifecycle of the CSI stage looks like, help with the planning of improvement, and measure the result of the improvement against the baseline. These vital features make the PDCA cycle a must-ask question for organizations when recruiting an ITIL expert. When asked this question, below is an example of what you’re expected to provide in your response.
Expected answer when asked “What is the Plan-Do-Check-Act (PDCA) cycle?” in an interview.
The Plan-Do-Check-Act cycle, also known as the PDCA cycle or Deming Cycle/Wheel, refers to a four-part lifecycle concept that many organizations use as the foundation for quality improvement activities.
It contains a series of processes that help organizations gather valuable information and lessons about the continual improvement of a product or service. The concept helps many organizations measure and control the results—gotten from the processes—so they can make correct decisions based on the result to improve their service or products later.
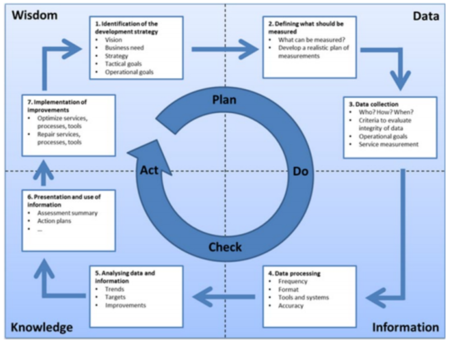
Q24. Define the four phases in the PDCA cycle?
![How to Implement the PDCA Cycle (Plan-Do-Check-Act) [Free Template]](https://paypant.com/wp-content/uploads/2022/01/how-to-implement-the-pdca-cycle-plan-do-check-act-1.jpeg)
This question is usually posed by interviewers to test your knowledge about the four gears of continual service improvement—the four phases of the PDCA cycle.
Improvement of service is a continuous and vital process for any organization which makes sense as to which why an interviewer would prioritize asking you this question in an interview. Below is a brief explanation of the four phases involved in the PDCA cycle.
Expected answer when asked, “Define the four phases in the PDCA cycle?” in an interview.
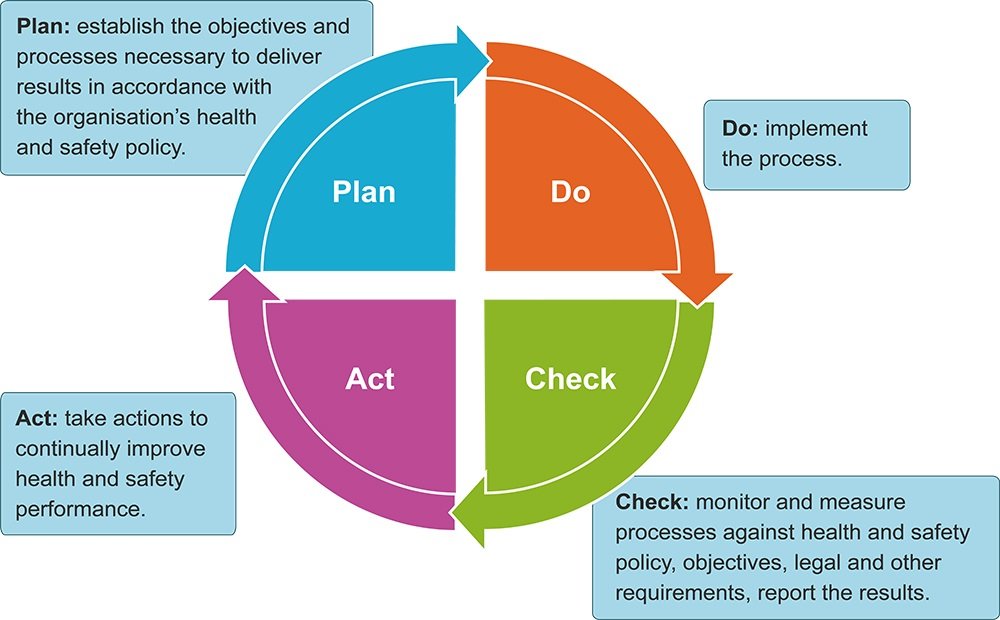
The PDCA cycle is composed of four different phases, which include:
- Plan: This is the first phase in the PDCA cycle, and it’s where the planning for the improvement occurs. This phase starts with a gap analysis to identify areas that need modifications, and then a plan—containing a series of improvement steps—is created to cover the gap.
- Do: This phase focuses on the implementation of the improvements defined in the plan. Usually, a project is initiated to cover the gaps discovered in the Plan phase. Here, a series of changes are implemented to improve the process.
- Check: The check phase involves monitoring, measuring, and reviewing the implemented improvement.
- Act: This phase is where the identified improvements are approved and implemented.
The PDCA cycle can be utilized for the improvement of any ITIL service management process.
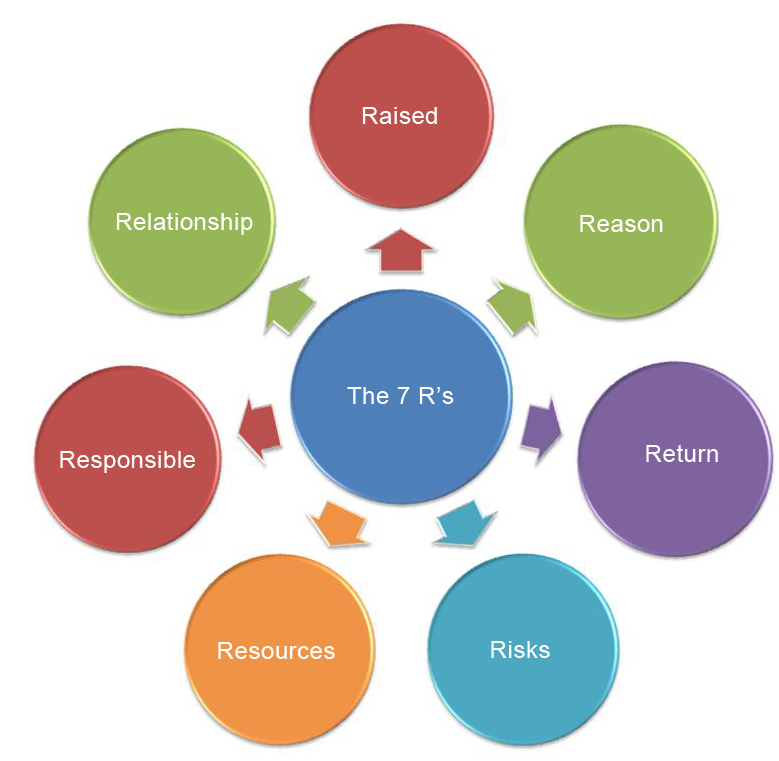
Q25. What are the 7 Rs of change management?
This question exposes some vital questions that organizations are actively finding answers to continually related to their change management process.
Properly answering this question would not only prove that you’re qualified for the job but can also help the organization find answers to the questions that have been consequently searching for answers to. Below is a sample of an excellent approach to answering this question in an interview.
Expected answer when asked, “What are the 7 Rs of change management?” in an interview.
As described in the “Business Perspective Volume II” in the chapter on business continuity, there are 7 Rs of change management. These are simple questions that organizations should ask (and answer) to help them evaluate their change management process’s effectiveness and change-related risk. The question this book employs organizations to ask includes:
- Who raised the change?
The major problem IT organizations face when it comes to change management is unauthorized changes. This problem is a result of the “siloed” sources and many entry points of change.
An excellent solution to these issues is to create a centralized system that records all the changes. And, the system should incorporate appropriate controls that define who is authorized to make the change in certain key areas. This system can also be helpful to an organization while performing audits.
- What is the reason for the change?
Providing an answer to this question can save an organization from making changes that introduce more risk than the benefit it offers. This question offers an organization a way of assessing changes against agreed-upon criteria before they can be approved and implemented. The requirements are developed to ensure appropriate prioritization of transition and identify potential gaps and misalignments before committing IT resources.
- What return is required from the change?
Answering this question would help an organization understand the return generated from the change—in terms of financial payback. This would help businesses determine which change is worth pursuing.
- What are the risks involved in the change?
An amount of risk accompanies every change, but the question is how much trouble is involved and how much is the organization willing to take. Some changes are better not implemented because of the risk involved, while some can be accepted and managed. You should make efforts to understand how the proposed change will affect your IT infrastructure in a best- and worst-case scenario.
Don’t also forget to assess the risk attached to not making the change. This would give you a degree of forethought on the change and help you identify and develop a regression strategy in the worst-case scenario.
- What resources are required to deliver the change?
IT infrastructure innovation requires two things: people and IT assets. The people aspect involves understanding the mechanisms that need to be in place to identify the necessary skills required to implement the changes and the availability of those skills—the same works for IT assets. You have to identify the assets that are required and where you can find them.
Also, you have to assess the impact on other projects: would there be any delay—in terms of cost and time—to other pending tasks, or would there be a need to re-allocate assets and people to implement the change?
- Who is responsible for the “build, test, and implement” portion of the change?
This question is supposed to be answered by anyone responsible for developing the application in the organization. The person who would assign these three functions must be well-defined and segregated to meet auditing and compliance requirements.
However, segregation of responsibilities should not be limited to application development. It can also be adopted to the entire change management process—including deployment and change requests.
- What is the relationship between this change and other changes?
Organizations with complex IT environments that are dynamic and have many concurrent changes would have some difficulties answering this question. The relationships between the changes need to be defined both internally and across other functional borders.
Failure to define these relationships can lead to sub-optimal or incorrect change sequencing, more extended periods of planned downtime due, and more. You can utilize shared scheduling, relationship mapping, and impact analysis of planned changes—from an integrated configuration management database—to help solve the problem.
By asking these seven questions and providing answers, IT organizations can maintain a high level of change discipline in their change management process.
Q26. What type of information is stored in a CMDB?
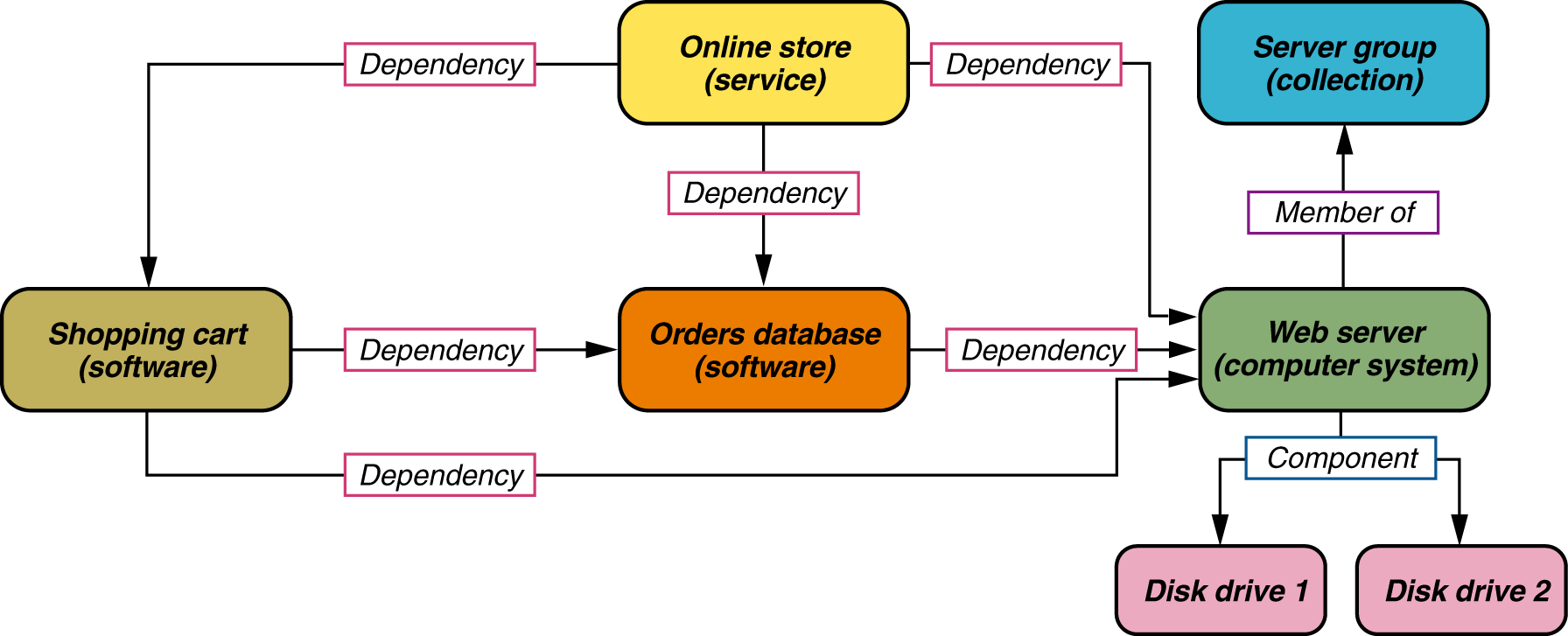
As one of the most important knowledge management systems in ITIL, it’s not a surprise that interviewers would want to ask this question in an ITIL interview. They expect you to have in-depth knowledge about all the knowledge management systems and CMDB is no different. Below is an excellent response to this question.
Expected answer when asked, “What type of information is stored in a CMDB?” in an interview.
CMDB or Configuration Management Database refers to a system that stores information about IT infrastructure and service management as entities called Configuration Items (CI) and the relationships between the entities.
CMDB forms the center of Configuration Management. Other information stored by the CMDB related to CI are problems, requests, changes, service history in the form of incidents, related CIs with a type of relation, Location data, used-by Information, Support Information, Status, Unique Identifier of the CI, CI type, etc.
The data stored by the CMDB can be utilized during essential processes such as asset, service request, change, problem, and incident management.
Proper utilization of the CMBD data in service management processes is vital for organizations to understand their IT environment. This will assist businesses in making precise and correct decisions concerning the services they provide.
Q27. What is the difference between end-users and customers?

While it’s easy to confuse both concepts as the same, organizations demand you have a clear definition of the two. Interviewers may ask this question just to test how well you can define the terms in ITIL, not just these two. Below is a well-defined answer to the question asked above.
Expected answer when asked “What is the difference between end-users and customers?” in an interview.
Although both terms are used interchangeably by many, they do not mean the same thing. An end-user refers to the person that ends up using the product of a company. The person might not necessarily be involved in the purchasing transaction of the particular product.
On the other hand, a customer is a person that purchases a product from a company. A customer might not be the end-user of the product. However, a single person can be both the customer and end-user of a product or service. If given more time, you can go ahead and explain more on this, with illustrations. It gives you an edge.
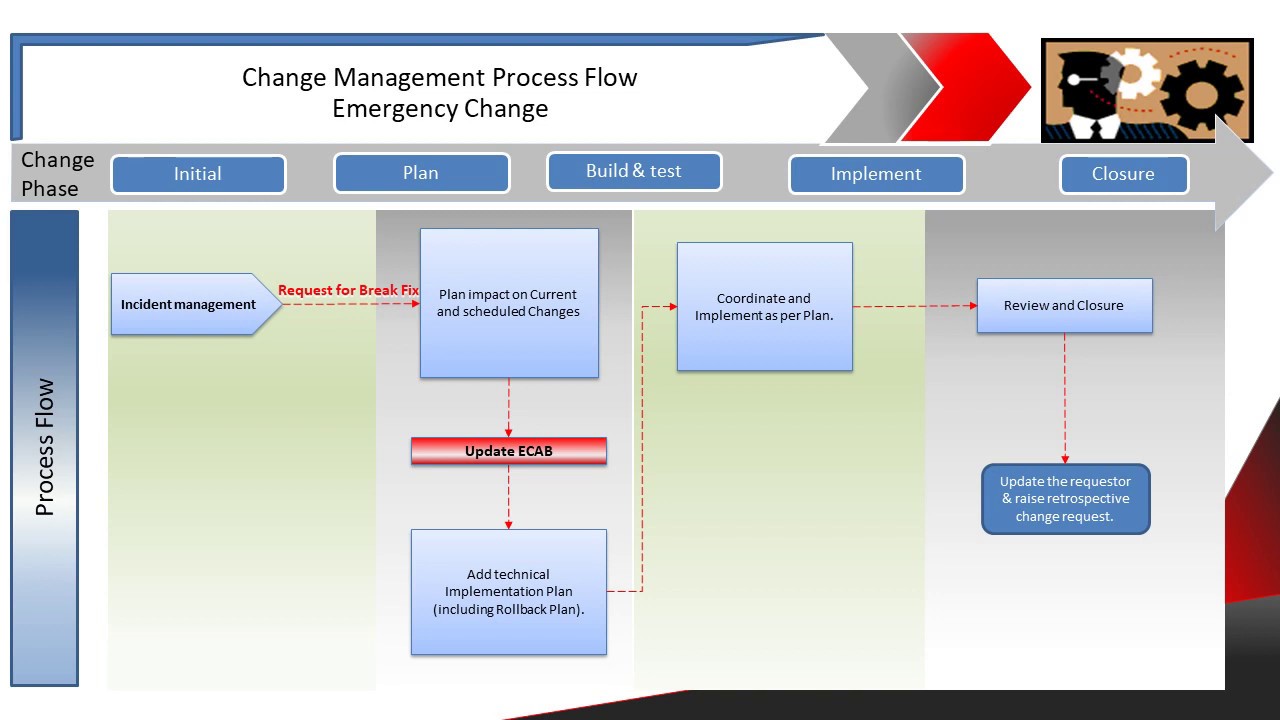
Q28. What is the difference between Expedite / Urgent Change and Emergency Change?
The most prevalent challenge that most organizations face while implementing a change management process is handling time-sensitive changes. This is due to the importance of urgency and efficacy while implementing these changes, which makes the overall control of the problem more difficult.
This question would determine if you understand this perplexing situation and how you can help your potential employer overcome it. An excellent answer to this question during an ITIL interview is given below.
Expected answer when asked “What is the difference between Expedite / Urgent Change and Emergency Change?” in an interview.
There are not so many significant differences between expedite/urgent change and emergency change. The term Urgent changes were used in ITIL version 2 but have now been replaced with Emergency Changes in the subsequent versions. However, while the name of the process has changed, the general premise has not.
An Expedite/Urgent Change refers to a change that does not conform to the standard approval and review time before achieving critical business requirements. These include the type of changes that need to be implemented as soon as possible.
On the other hand, an emergency change means a change with the highest priority possible in an organization. These changes are applied quickly, and in most cases, aren’t tested before being implemented. Decisions about these types of changes are made by balancing the rewards and risks present.
Q29. What do you mean by CAB?
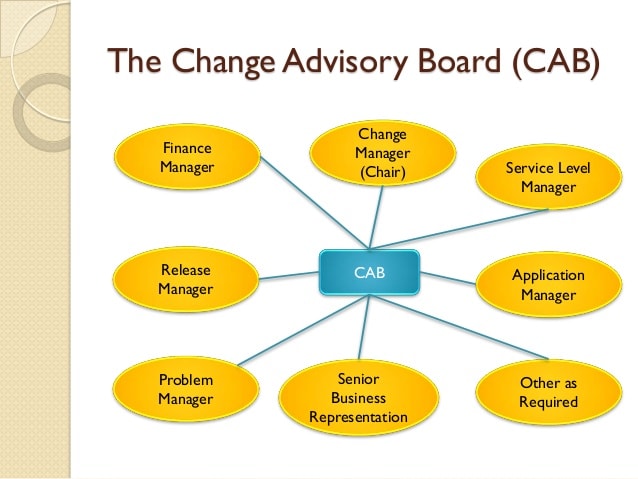
If you’re familiar with the terminologies in the Change Management process, this question would be easy peasy. The main reason why interviewers ask this question is because of the importance of the CAB to the change management process. CAB refers to a team of people responsible for making positive changes to the service delivery model without disrupting the business. Now, what approach is the best when answering the above question in an ITIL interview?
What’s the expected answer when asked, “What do you mean by CAB?” in an interview?
CAB or Change Advisory Board consists of a group of people—usually technical staff and crucial decision-makers—responsible for assessing the changes before or after they are implemented into any IT environment. The people that are often members of the CAB in an organization usually include:
- Application Manager/Engineer
- Business Relationship Managers
- Information Security Officer
- Operation Manager
- Senior Network Engineer
- Service Desk Analyst
CAB meetings are typically conducted by the CAB Manager. The meetings can be scheduled to hold regularly—either monthly or weekly—depending on the size of the organization and resources available.
Q30. What is a PIR?
The PIR process is important to organizations in ensuring they get the best from implementing projects. The process is initiated after the completion of a project to measure the effectiveness of the project and draw lessons for the future.
This question helps the interview assess your level of understanding of the concept “PIR”, so you should make your response as comprehensive and meaningful as you can. You can take a cue from the below example to form your approach to the question in case you are asked in an interview.
Expected answer when asked, “What is a PIR?” in an interview.
A PIR or Post Implementation Review can be defined as a process initiated after the successful implementation of a project or changes to assess the effectiveness of the change. The primary purpose of a PIR process is to evaluate the impact of the changes, that is, have the change objectives have been met, did the project run as expected, which will help organizations to be able to maximize the benefits they get from projects and changes.
PIR helps organizations to find solutions to these important questions:
- Did the change achieve the expected result?
- What is the impact of the change on the customers?
- Were the allocated resources utilized effectively during the process?
- Did the change meet the budget requirements?
Q31. Explain the service portfolio, service catalog, and service pipeline.
This type of question is very common in an ITIL interview, most often, an interviewer would ask you to explain or differentiate between different but closely related concepts.
The primary reason for this is to assess your in-depth knowledge about the different parts of the ITIL framework. For example, the above question features terms that are native to the service design and strategy stage. You can find how to answer the above question in an interview below.
Expected answer when asked “Explain the service portfolio, service catalog, and service pipeline” in an interview.
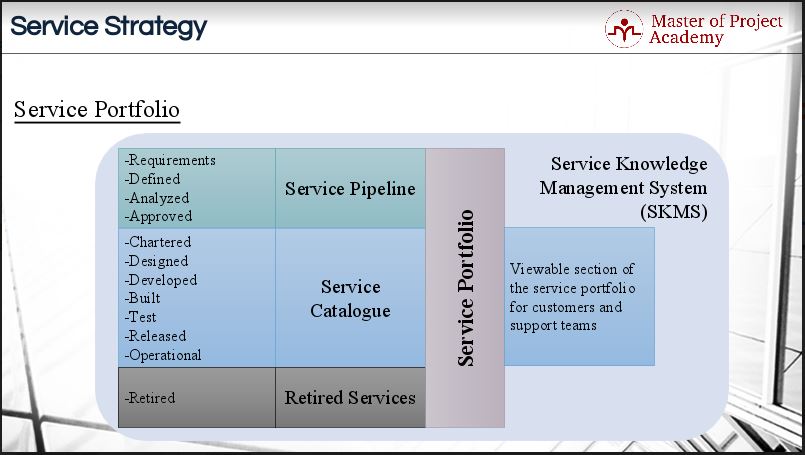
Service Portfolio: Information and data related to all services in an organization are stored in a central repository referred to as a Service portfolio. Here, all the services in an organization are listed, showing their history and current status. The major descriptor of the service portfolio is the SDP (Service Design Package).
The service portfolio consists of three integral components which include the Retired services, service catalog, and service pipeline.
Service Catalogue: A service catalog refers to a listing that showcases all the available services and products offered by the organization to its users. One distinctive feature about the service catalog is that its listings only show services or products that are currently available, not the ones that are no longer available (retired) or yet to be developed.
Service catalogs are visible to the support team and customers as websites, portals, or software packages. Users can add or install any item, application, software, or hardware they want upon request.
The service catalog helps organizations to improve communication between the service desk and users. It acts as a monitoring system that reports the updates for user requests and shows the progress of the service desk in processing these requests.
The service catalog can also be divided into categories if there are many different services offered through the service desk. This will include a comprehensive list of the services and products under each category. It can come in handy for users who need to find what they need from an extensive catalog. For example, you can have a record divided into the business and technical logs, which represents the categories.
Note that in the ITIL v3 framework, the Service Catalog was incorporated as one of the Service Strategy practices. But, with the recent upgrade to the ITIL v4, it has been included as one of the Service Management practices.
Service Pipeline: This refers to a future-based concept that contains services that are not yet in a live environment (either proposed, undergoing modifications, or still under development). It is one of the parts of the Service Portfolio and contains services that might eventually be added to the service catalog. The Service pipeline is operating during the Service Transition Stage.
Q32. What is the freeze period?

Freeze periods are important to businesses as it helps maintain balance in their IT environment and also contribute towards preventing unexpected errors to service. In case you’re asked in an interview, you can take a cue from the solution given below.
Expected answer when asked, “What is the freeze period?” in an interview.
The freeze period or change freeze period is a change management process that ensures that services are available to users when most needed. The time or period where the services are less needed is referred to as “change freeze periods”.
It defines a period during which additional caution and scrutiny of changes are warranted. There would be no significant project deployments or changes to critical services during this period. Although, there can be some exceptions that would require approval from three or more operational Managing Directors.
Q33. What is CSF?

CSFs are vital to an organization’s success, and for them to be effective, it has to become an integral part of the company and be consistently worked on. It may sound like a complex process, but it’s a simple concept that organizations and ITIL experts should understand. Below is an example of an excellent response to the question “What is CSF?” when asked in an ITIL interview.
Expected answer when asked “What is CSF?” in an interview.
CSFs, also known as Critical Success Factors, refer to the critical elements required to succeed and for an objective or strategy to be implemented. You can mostly find these elements in a business strategy, the vision of an organization, or a mission statement. They represent vital requirements that must be met before a project/objective can be successfully achieved—CSFs are the primary driving force of business strategies.
Although these CSFs can be different depending on the business, they are mostly related to finances. Companies can use CSFs to identify how they can meet market demand, improve productivity, and more. Some of the benefits of having CSFs include decreased complaints, increased customer and cash flow, and profits.
Q34. What is data leakage?

This question addresses one of the major challenges that most organizations are facing today. Interviewers usually use this question to determine how well you understand this problem and whether you can help in solving it. Ensure to properly answer these types of critical questions that apply to the organization you want to work it as they could be vital towards the success of your interview.
Expected answer when asked “What is data leakage?” in an interview.
Data leaks refer to a scenario where unauthorized third parties gain access or transmit the organization’s sensitive information from inside a privileged access point to another server or location. Most data leakage events involve compromised data integrity and made public to the world or untrusted groups, usually through online channels.
Data leaks can have short or long-term impacts, which can be devastating, especially to organizations in the business of handling sensitive customer information. The immediate consequences may include stock price drops, legal fees, PR costs, regulatory fines, and more. But, the long-term effects, such as reduced customer trust, loss of control over intellectual property, reputational, and more, can cost an organization lots of money and a massive decrease in revenue over time.
Q35. Which factors contribute to data leakage?
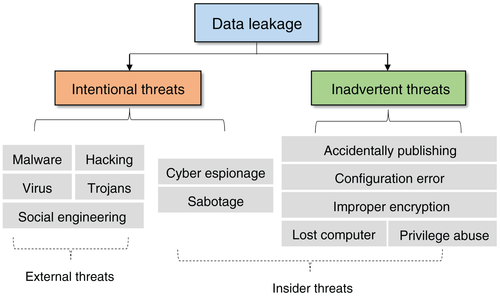
Different factors can cause the leakage of an organization’s information or data. Data leakage can occur due to accidental exposure events—usually due to the negligence of an employee—or by an attack from inside adversaries.
However, most data leakage cases that have occurred are usually due to unauthorized access or data breach to a system, account, database, or private network traditionally carried out by a hacker. When asked the above question in an interview, below are some of the factors that contribute to data leakage.
Expected answer when asked “Which factors contribute to data leakage?” in an interview.
The factors that contribute toward data leakage in organizations include:
1. Weak and Stolen Passwords
A considerable percentage of data leakages cases reported says the breach was perpetuated often due to a weak or lost password—hacking attacks only account for a small percentage—which exposed the vulnerability that the opportunist hacker exploited.
A statistical report reveals that 4 out of every five breaches considered “hacks” in 2012 have their root causes related to weak or lost passwords. Organizations should use complex passwords to avoid data leakage due to inadequate or stolen passwords—smartly combining both lower- and upper-case letters with numbers and special characters. Also, passwords should never be shared.
2. Application Vulnerabilities
What’s worse than having a door broken down is not having a door at all. A poorly designed network system or software application will give hackers room to maneuver straight through to your data. Organizations can fill these loopholes by ensuring that all hardware and software solutions are continually updated and patched.
3. Malware
Malware, either used directly or indirectly, has become a growing trend of web attacks. The term “Malware” defines malicious software that can be executed without authorization and provides hackers access into your system and even other connected systems. An excellent solution to prevent malware is to avoid accessing shady websites or opening emails that look suspicious. These are the most common tactics being used to spread malware.
4. Too Many Permissions
Having overly complex access permissions leave lots of loose ends for hackers to exploit. Not correctly defining who gets access to what within an organization can lead to the wrong permissions falling into the hands of evil people. When it comes to licenses, simple is better.
5. Insider Threats
Of all types of data breaches, the most difficult to deal with are perpetrated by someone close to you. There is a saying that goes, “Your enemies are at your backyard, but the most dangerous of them all lives in-house with you.” This phase can’t be any more accurate; the people that have permission to access your data are usually the ones most likely to cause a data breach.
Conduct in-depth background research before hiring someone that would hold sensitive positions in your organization. This research process will help you know who you are dealing with and take certain precautions when needed. You also can complement this with data safety and security training for staff.
6. Physical Attacks
More than web/online security, the physical safety of data is the most vital. Hackers can go as far as breaking into your organization to have access to your computer systems and network. So, you should also prioritize your organization’s security and report any suspicious movement/activities to the authorities.
7. Improper Configuration/User Error
We all make mistakes and err; that’s what makes us human. However, some mistakes are avoidable. By hiring a correct professional to handle the security of your data and complex procedures and processes, user errors are reduced to a minimum and limited only to areas that can lead to a significant data breach.
Q36. How to prevent data leakage?

As an IT expert, organizations would expect that you are familiar with the safety practices for preventing data leakage. This assumption is what the interviewer wants to confirm with this question. You can pick ideas below of what is expected from you when asked this question in an ITIL interview.
Expected answer when asked “How to prevent data leakage?” in an interview.
The following are ways by which you can keep your data leak-proof and secure:
1. Identify critical data
The first step towards protecting a company’s information is to define which data requires the most protection. This will help organization categorize their data and better utilize the data loss prevention (DLP) software to protect sensitive information. The priority of data protection varies depending on the industry. Examples of critical data may include; strategy checks, financial statements and blueprint, and PHI.
Due to the high reliance of DLP on the proper categorization of data, there is a need for an organization to have a data protection strategy that defines sensitive information and how they are to be handled.
2. Monitor access and activity
Another critical step towards preventing data leakage is to ensure traffic on all networks is closely monitored. To get the complete picture of your network in real-time, you’ll have to develop a system to automatically identify, map, and track all the activities that happen across your entire business infrastructure.
This process is primarily effective because an average hacker would spend at least six months scouting out your network before actually breaching the system. An excellent way to protect your organization is to use monitoring tools to supervise activities and access and alert the administrators when detected anomalous behaviors. This system would help organization stop potential threat before it happens.
To add another layer of protection, an organization can utilize a Data Activity Monitoring (DAM) solution which helps in discovering unauthorized actions. Unlike DLP, which targets networks and endpoints, DAM is focused on the database. Concurrently applying both solutions will give organizations a layered defense system that utilizes monitoring and alerts processes to detect and block suspicious users or activities.
3. Utilize encryption
All sensitive, confidential, or private information should be encrypted. This method doesn’t provide 100% data security but has proven to be one of the best securing sensitive data. When appropriately done concurrently with an excellent critical management process, encrypted data would be useless and unreadable when stolen.
Encrypting all types of data across different points of your network would provide organizations with the ability to defend against even the most advanced attacks. This defense mechanism works best when the encrypted network is proactively monitored and managed.
4. Lock down the network
The ability to lock down the network should be one of the organizations’ top priorities when making efforts to prevent data leakages. This effort can also be reinforced with frequent practice testing of good practices and tutorials for employees.
5. Endpoint security
Data within an IT infrastructure can exit the network via exit points, and these points are weak spots lurking hackers seek to exploit to perpetrate a data breach. Organizations can minimize the risk of data loss through these exit points by utilizing DLP solutions to supervise and act at these exit endpoints. The DLP solutions allow an organization to monitor which information is exiting the network, when, and on which device or channel it is leaving.
With the prevalence adoption of the “Bring Your Device” practice in many businesses, securing the endpoint of a company’s information has become essential. Due to the numerous platforms that must be supported and the geography, security while adopting BYOD can be complex. However, companies can monitor the movement of data by putting adequate controls in place.
Gaining permission and access to monitoring the activities on the personal devices connected to the organization would provide the company with a comprehensive view of their network. In the absence of proper endpoint management, organizations can be utterly oblivious to data breaches worsening vulnerabilities.
Fundamental data security practices, such as utilizing endpoint protection tools, secure web gateways, intrusion prevention systems, and network firewalls, protects the company’s data. Also, implementing best practices and employing effective security technologies can contribute a lot towards ensuring data security.
While there is no hackproof method to prevent data leakage, the best way to secure your company’s sensitive information is by adopting a multi-facet approach towards data security. You can concurrently adopt data encryption, identifying critical data, endpoint management practices, retaining control of your network, and a combination of DLP or DAM solutions into a customizable thick-layered security system to secure your organization’s data.
Q37. What is an XSS attack?
Many organizations of different sizes and types have fallen victim to this type of web attack which has become prevalent with the advancement of web networks.
Interviewers usually ask this question to measure your level of understanding of the attack including how it works, the impact on an organization, and how you can prevent it. Below is an excellent example of what the interviewer is expecting when they ask the above question.
Expected answer when asked, “What is an XSS attack?” in an interview.
An XSS attack or cross-site scripting attack refers to a web attack that injects malicious code into a vulnerable web application. This type of attack is unique because the attack is not directed towards the application itself, but instead, it is the users of the application that is targeted. The impact on the business’s reputation and customer relationship can be devastating, depending on the severity of the attack.
While the damage caused by the attack may include page content modification to mislead visitors into giving out their personal information, a trojan horse has been activated, and user accounts have been compromised. In extreme cases, the web session cookies are tampered with, giving the perpetrator the freedom to impersonate and abuse real users’ accounts.
Q38. What are the different types of XSS attacks?
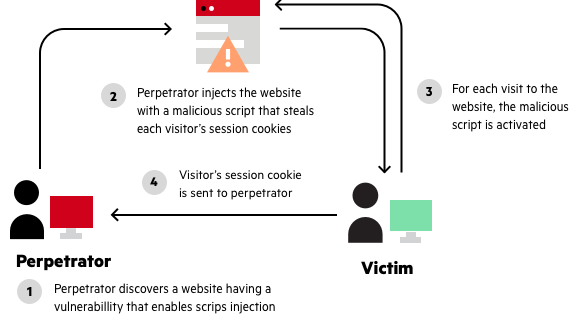
The first step in stopping an attack on the data of an organization is understanding how it is being perpetuated. Most organizations would require that their potential ITIL expert is well-versed with how these attacks work and how to secure themselves and the company against them. An excellent approach to cracking this question is given below.
Expected answer when asked, “What are the different types of XSS attacks?” in an interview.
All XSS attacks can be categorized under three main groupings. They are:
- Reflected XSS: Reflected XSS is the most straightforward type of cross-site scripting attack. The attack is perpetrated by sending data in an HTTP request to an application, which in immediate response includes that data unsafely. Here, the malicious script in question arises from the current HTTP request.
- Stored XSS: Another significant type of XSS attack is Stored or second-order or persistent XSS. Here, data is sent from an untrusted source to an application which is then included in its later HTTP responses in an unsafe way.
The channel of submitting the data in question might be from the contact details on a customer order, user nicknames in a chat room, or comments on a blog post. Unlike the former cross-site scripting attack, the malicious script comes from the website’s database.
- DOM-based XSS: A DOM-based XSS or DOM XSS attack is perpetuated through the presence of some client-side JavaScript in the application, which processes data from untrusted sources in an unsafe way—the data are written back to the DOM.
The distinctive characteristic of this type of cross-site scripting attack is that its focus is on the client-side code and not the server-side code.
Q39. Why is information security policy important?

The security of a company’s information is the topmost priority of any organization. And, writing an information security policy would help the organization have a sense of direction when securing their data. This question touches on a sensitive topic that many organizations prioritize the most, and the probability of being asked in an interview is high.
Interviewers can decide whether your fit for the job or not using this question, so you can’t afford to get things wrong. Take a cue from the solution below to know how to answer the above question in an ITIL interview.
Expected answer when asked “Why is information security policy important?” in an interview.
Along with the different benefits that come with having an effective security policy, the primary reasons why security policies are essential to organizations include the following:
- Information security policy contains well-defined responsibilities that organization’s employees are expected to carry out as regards security
- Information security policy helps identify and manage the risk appetite and managerial mindset of an organization’s management.
- Information security policy provides guidelines for a control framework that organizations can build to defend against internal and external threats.
- Information security policy functions as a support for the organization’s ethical and legal responsibilities.
- Information security policy serves as a mechanism that ensures individuals comply with the standard guidelines regarding information security.
Q40. What are the most popular workaround recovery options?

Before attempting to answer this question, note that many recovery options can be utilized during the design of the IT Service Continuity Strategy. Still, the most feasible choice would depend on the primary cause of the service unavailability. The interviewer wants to test your knowledge on the most popularly adopted ones. Below are six of them you are expected to talk about when you are being asked the above question in an ITIL interview.
Expected answer when asked “What are the most popular workaround recovery options?” in an interview.
The most commonly used workaround recovery options by organizations include:
- Manual workaround: The manual workaround option provides an organization with a cheaper, faster, and efficient way of recovery in highly complex situations. However, this workaround option can only be effective for a limited amount of time.
- Reciprocal arrangements: This method revolves around organizations within the same industry agreeing to share resources in the event of a catastrophic incident, working as a means of ensuring contingency for business services. However, this type of arrangement is rare due to the specific nature of the IT industry.
- Gradual recovery: Here, the infrastructure and power are provided with an empty facility without any computing equipment. Gradual recovery is only feasible when the service recovery is expected to take days or even weeks—the computing hardware and equipment would be purchased, installed, and set up later. Another name for this recovery method is “cold-standby.”
- Intermediate recovery: This method is called “warm standby” and includes everything provided under gradual recovery. The difference between the two recovery methods is the inclusion of actually required computing equipment. Here, all the necessary equipment has been set up and configured. Also, Intermediate recovery is faster than gradual recovery.
- Fast recovery: Fast recovery, also known as “hot standby”, has everything listed under the intermediate recovery; however, the production site does not mirror the data and equipment. This recovery method requires less time but may lack data or services.
- Immediate recovery: In contrast to “fast recovery”, here, the primary area, data, service, and equipment are split images of the secondary location. This recovery method is the most expensive since everything is doubled.
Proper planning should be considered before the occurrence of any incident that may cause service disruption due to the varying duration required for service restoration and the complexity of these recovery options.
Q41. What are the various service providers?

A service provider usually refers to an entity or individual that provides IT services and solutions to organizations and end-users. There are different types of service providers in ITIL, and the interviewer aims to assess your knowledge about the different types with this question. Below is a comprehensive guide on which you can model your response when asked “What are the various service providers?” in an ITIL interview.
Expected answer when asked “What are the various service providers?” in an interview.
There are three types of service providers:
1. Internal Service Provider
ISPs are dedicated service providers who are often incorporated within a single corporate unit. The business units could be part of a giant corporation or parent company. The business functions that provide services to various elements of the organization include IT, human resources, logistics, administration, and finance. They are supported by the company’s overhead and are supposed to function precisely within the company’s mandates.
ISPs gain from a close relationship with their owner-customers, reducing some of the expenses and risks of doing business with other parties. Because ISPs are assigned to specific business units, they must have a thorough understanding of their goals, plans, and activities. They are usually highly specialized, focusing on designing, adapting, and supporting specific applications or business processes.
Internal market spaces are where ISPs operate. The development of the business unit to which they belong limits their expansion. Each business unit (BU) may have its Internet service provider (ISP). Because ISPs often operate on a cost-recovery basis with internal finance, their success is not judged on revenues or profits. The owner business unit or firm is responsible for all charges.
2. Shared Services Unit
Finance, information technology, human resources, and logistics aren’t necessarily at the heart of a company’s competitive advantage. As a result, they don’t need to be maintained at the corporate level, requiring the attention of the CEO’s team.
Instead, such shared functions’ services are merged into a single autonomous unit known as a shared services unit (SSU). To gain a more decentralized organizational structure, SSUs can take another approach by serving business units as direct customers.
By adopting the practices of external service providers, SSUs can also create, expand, and maintain a steady internal market for their services. Risks and expenses are shared as in an external service provider function across a large base promoting the better utilization of opportunities across the business units.
However, unlike external service providers, there is lesser protection through core competencies and strategic values. Their performances are measured against external service providers which they model after in terms of operating models, strategies, and business practices.
Examples of Type II customers includes enterprise-level strategies, known stakeholders, and business unit under a corporate parent. The prices offered by Type II can be lowered than external services providers due to the internal autonomy to function as a business unit and leveraging on corporate advantages.
Unlike other providers, Type II providers are not limited by business unit-level policies when it comes to their decision-making process. By adopting market-based pricing, they can impact demand patterns and unify service offerings across business units.
Type II and Type III service providers may find themselves in circumstances where they are required to offer their services both internally and externally. These situations require critical strategic decision-making to make services available both internally and externally providing a well-controlled management structure. Outsourcing current services are not always the right way to go.
3. External Service Provider
This type of service provider focuses on the delivery of its IT services to external customers. Here, customers require Type III providers to have readied capabilities through their business strategies. The only advantage that Type III providers have over the other types is the freedom to pursue opportunities and increased flexibility.
Unlike other service providers, ESPs can consolidate demands to cut down unit costs and offer competitive prices. Also, internal service providers such as Type I and Type II don’t have specific business strategies in place like ESPs. The service from external providers is then required by ISPs outsourcing strategies.
Access to information, experience, scale, breadth, capabilities, and resources beyond the company’s reach or the size of a well-considered investment portfolio could be the reason. Reductions in the asset base, fixed expenses, operational risks, and the redeployment of financial assets are frequently required by business strategies.
ESPs’ experience is frequently not confined to a single company or market. For customers, the breadth and depth of such expertise is frequently the single most distinguishing source of value. The range stems from providing a variety of consumers or marketplaces. Doing multiples of the same thing gives you more depth.
ESPs, in particular, operate under a large-scale shared services model that has been extended. In comparison to ISPs and SSUs, they assume a higher level of risk from their clients. However, their customers – some of whom may be competitors – share their expertise and resources. This means that rival clients have access to the same collection of assets, reducing any competitive advantage that those assets might have provided.
Q42. What is the purpose of Service Transition?
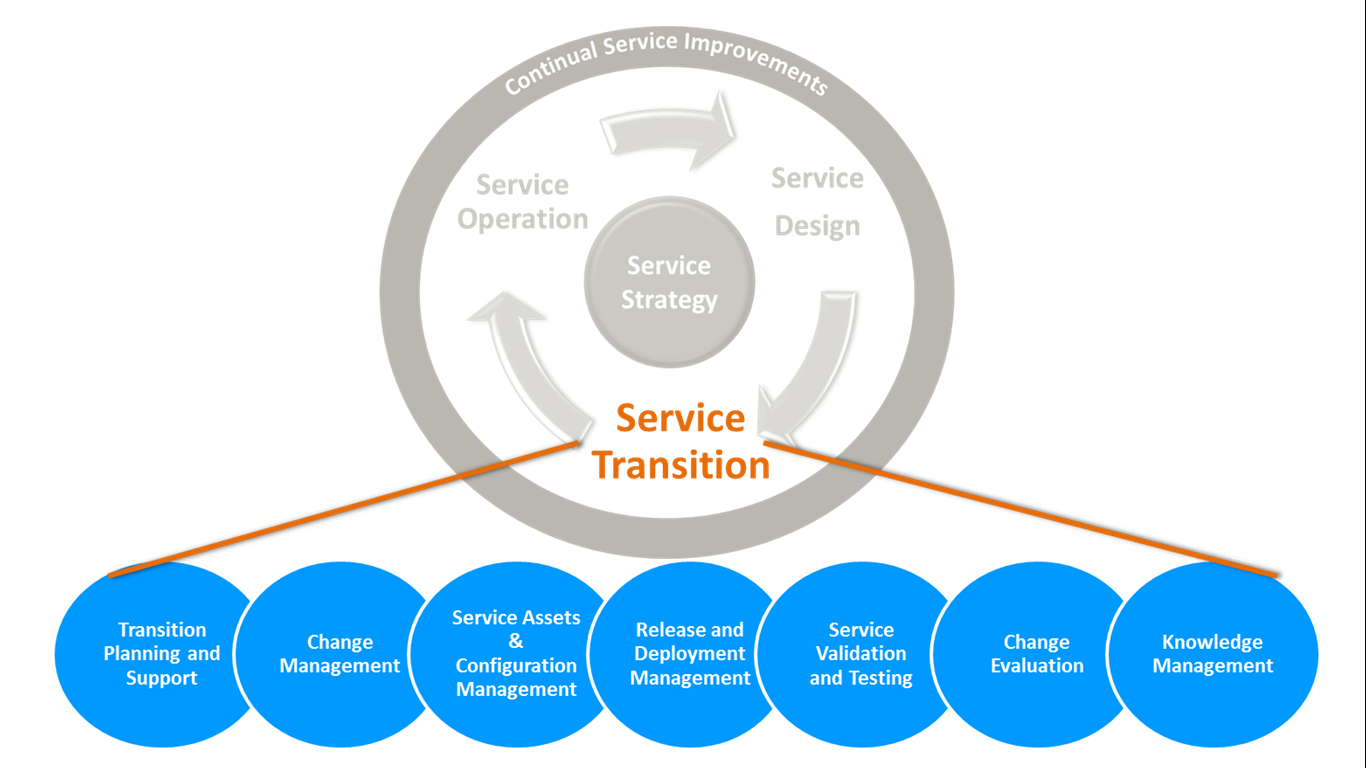
The service transition stage is an integral part of the ITIL lifecycle that involves the service strategy and design stage. The interviewer expects you to provide the primary objectives and goals that the organization can achieve by following the practices in the phase. Now, how do you answer the above question in an ITIL interview?
Expected answer when asked “What is the purpose of Service Transition?” in an interview.
The purpose of the Service Transition stage include:
- To effectively and efficiently plan and manage the changes that occur to service.
- To reduce or eliminate the risks that come with newly introduced, modified, or retired services.
- Ensuring that newly introduced, modified, or discontinued services meet the agreed business requirements and expectations discussed in the service strategy and design stage.
- Deploying the service releases into environments that support them adequately.
- Make sure that the service changes create the expected value for the business.
- Providing the necessary knowledge and information about services and service assets.
- Setting the appropriate expectations for the performance and usage of new or changed services.
Q43. What is the difference between ITIL and COBIT?
While ITIL and COBIT are both frameworks used to implement ITSM, they are different in many ways. Organizations need to know the type of framework that works best for their type of industry, this can be a determinant factor in the success of the business. Check out some of the major differences between the two frameworks below to draw some ideas on how to answer the question when asked in an ITIL interview.
Expected answer when asked “What is the difference between ITIL and COBIT?” in an interview.
The differences between ITIL and COBIT are:
- ITIL is also known as Information Technology Infrastructure Library, while COBIT stands for Control Objectives for Information and Related Technologies.
- ITIL is mainly used for IT service management, while on the other hand, COBIT enables the integration of IT.
- ITIL helps with the implementation of the guidelines of a business, while COBIT allows users to derive guidelines for business operations.
- There are five components of ITIL: continuous service improvement, service operation, service transition, service design, and service strategy, but for COBIT it consists of process descriptions, maturity models, frameworks, control objectives, and management guidelines.
- ITIL focuses more on IT service management and follows a bottom-up approach, while COBIT focuses more on IT service governance and follows a top-down approach.
Q44. What are the objectives of Incident Management?
Interviewers ask this question to test your knowledge about the reasons why an organization should adopt an incident management process. In case you are asked in an interview, check out the sample solution below to develop an idea of how you’re expected to answer the question during an ITIL interview.
Expected answer when asked “What are the objectives of Incident Management?” in an interview.
The primary purpose of Incident Management is to ensure that the agreed service operation is recovered as soon as possible following an incident. As an integral part of service management, incident management has the following objectives:
- Ensuring that all required data relating to every incident is documented.
- It ensures that every incident is effective and efficiently processed using a set of standardized procedures and activities.
- Ensuring that all incidents are resolved in the most cost-efficient way using well-defined functional escalation levels
- Ensuring that incidents are investigated by experts—either internal or external—or qualified members of staff by adopting functional and hierarchical escalation procedures
- Categorize and prioritize incidents according to the potential threat, impact, and urgency for proper scheduling of its resolution in a business-oriented way.
Q45. What is the process of ITIL Incident Management?
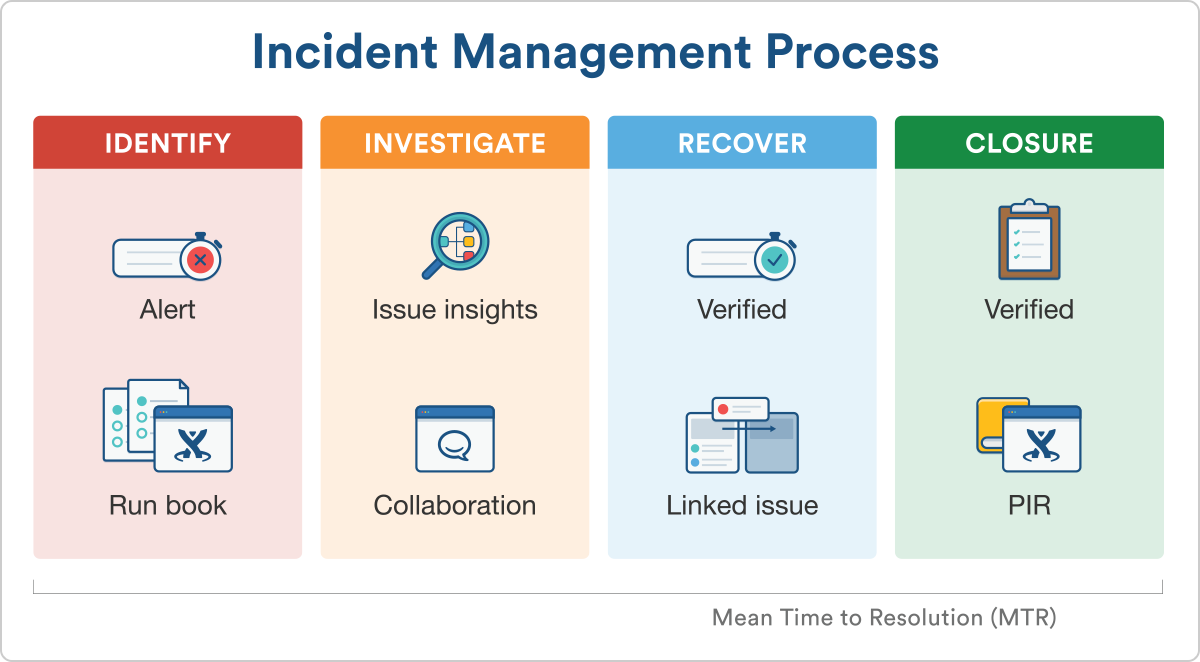
Incident Management is not as complicated as it seems, and organizations can follow the incident management practices easily. There are five main processes involved in the ITIL incident management phase which have been discussed below.
Expected answer when asked “What is the process of ITIL Incident Management?” in an interview.
The ITIL Incident Management process is divided into five significant steps. These steps provide a holistic approach to incident resolution and help organizations respond to incidents effectively. They are:
1. Incident Identification, Logging, and Categorization
The main methods of identifying incidents include manual identification, using user reports, or solution analyses. After the identification phase, the incident is logged, and categorization and investigation can commence. Categorizing incidents helps assign priority to incidents and determine how they should be handled and response resources distributed.
2. Incident Notification & Escalation
This step is where incident alerting takes place; the timing of the alert may differ based on how incidents are categorized or identified. In case of minor incidents, notifications may be sent or details logged without an official warning. Escalation is based on who is responsible for response procedures and the categorization assigned to an incident. Automating incident management would allow transparent escalation to occur.
3. Investigation and Diagnosis
The investigation by the team into the cause, type and possible solutions of an incident usually commences after the incident tasks have been assigned. After an incident is diagnosed, you can determine the appropriate remediation steps. This includes notifying any relevant authorities, customers, or staff about the incident and any expected disruption of services.
4. Resolution and Recovery
The resolution and recovery phase are concerned with eliminating threats or root causes of incidents and ensuring all systems functions are back to normal. However, this may require multiple stages depending on the incident severity or type to prevent future occurrence of that incident.
5. Incident Closure
This step usually involves evaluating the actions taken during incident response and finalizing documentation. The evaluation process allows teams to identify critical areas in need of improvement and take proactive measures to prevent incidents.
Additional tasks during incident closure may include presenting a retrospective or report to customers, board members, or administrative teams. This report can go a long way in rebuilding the lost trust due to the impact of the incident and add transparency to your service operations.
Q46. What is the purpose of Problem Management in ITIL?
Before answering this question, you must know the difference between a problem and an incident. The two does not necessarily mean the same thing, even though it’s used interchangeably by some. Below is an excellent example of the response the interviewer expects from you when they ask the question above during an ITIL interview.
Expected answer when asked “What is the purpose of Problem Management in ITIL?” in an interview.
The primary purpose of the problem management stage is to minimize the occurrence and impact of incidents through proper management of known errors and workarounds and identification of the potential and actual causes of incidents.
While incidents and problems are closely related, they are not essential managed the same way. Incidents may have catastrophic effects on business processes or users and require urgent attention to ensure the continuity of regular business activities.
On the other hand, problems are the resulting events that occur due to the presence of one or more incidents. The problem management process is responsible for the investigation, analysis, and identification of causative incidents recommends temporary workarounds, and develops permanent fixes. The purpose of the problem management processes is to reduce the impact and chance of an incident occurring in the future.
Q47. What are the different stages in the Problem Management Process?
This question is designed to test your knowledge of the different processes involved in problem management. As an important process to organizations, interviewers are most likely to ask a question related to this during an interview so prepare for such. You can take a cue from the expected answer below to prepare for this question in case you’re asked in an ITIL interview.
Expected answer when asked “What are the different stages in the Problem Management Process?” in an interview.
There are three different stages of Problem Management. They are:
1. Problem Identification
The activities involved in the problem identification stage includes:
- Collect information from project teams, test teams, and internal software developers for analysis
- Analyzing Information received from suppliers and partners.
- Identify recurring or duplicate issues
- Discover the potential of an incident recurring during the incident management process.
- Performing trend analysis of incident records.
2. Problem Control
This stage provides problem analysis and records information about known errors and workarounds. Problems are categorized and prioritized depending on the amount of risk they pose and the severity of impact to services. The problem with the highest probability of catastrophic service and service management should be focused on first.
During incident analysis, take note of the complex relationships that may exist between incidents with interrelated causes.
A holistic problem analysis would cover every contributory cause, including those responsible for the occurrence of the incident, worsening it, or even prolonged the incident. With problems that take an extended period, you need to develop a workaround for future reference to help manage the problem based on prior knowledge about the issue.
A workaround refers to an alternate solution to a problem or incident focusing on reducing or eliminating the probability or impact before a complete resolution is identified. A typical example of a workaround could be failover to secondary equipment or restarting services in an application. While there is no time restriction on when workarounds should be documented into the problem records, they should be continually reviewed and improved at the end of problem analysis.
When there is no feasible or cost-effective resolution to a problem, an effective workaround can be a permanent solution to incidents. The incident is still regarded as a known error; however, the documented workaround is applied when a related incident occurs. For faster application and greater efficiency, organizations can automate the deployment of workarounds. Also, every workaround should be well-defined concerning the context to which it applies and the symptoms.
3. Error Control
Error control refers to a series of activities responsible for managing known errors and can also help identify a potentially permanent solution to the error. Analysis should be done from three perspectives; benefits, risk, and cost, if implementing a permanent solution will require a change control.
This stage also performs frequent re-assessments of known errors which haven’t been resolved, considering the effectiveness of workarounds, cost of permanent resolutions, and the overall impact on service availability or customers. Workarounds are also regularly evaluated to measure efficacy and identify potential areas that require improvement based on the assessment.
Q48. What are the objectives of the IT Service Continuity Management (ITSCM)?
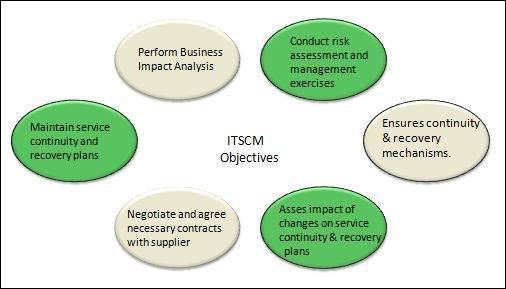
ITSCM is an integral part of the ITIL service delivery stage. It aims to restore the service performance and availability to its highest possible level even after a disaster-level incident. Below are the objectives of the ITSCM process, which should serve as a guide for you when faced with the same question in an ITIL interview.
Expected answer when asked “What are the objectives of the IT Service Continuity Management (ITSCM)?” in an interview.
Some of the main objectives of IT service continuity management (ITSCM) are:
- Agrees to contracts and performs negotiations with suppliers to provide the required recovery capability.
- Increased availability of services through the implementation of proactive measures wherever it is economical.
- Measure and monitor the impact that changes to IT infrastructure have on ITSCM plans.
- Control and implement the plans for IT recovery and service continuity in alignment with the overall business continuity plans.
- Performs management activities risk analysis and business impact analysis regularly
- Ensures the installation of suitable continuity mechanisms capable of reaching or exceeding business continuity targets.
- Helps to minimize costs that cannot be removed effectively
- Advice and assist with any recovery and continuity-related issues.
Q49. What do you mean by Event Management in ITIL?
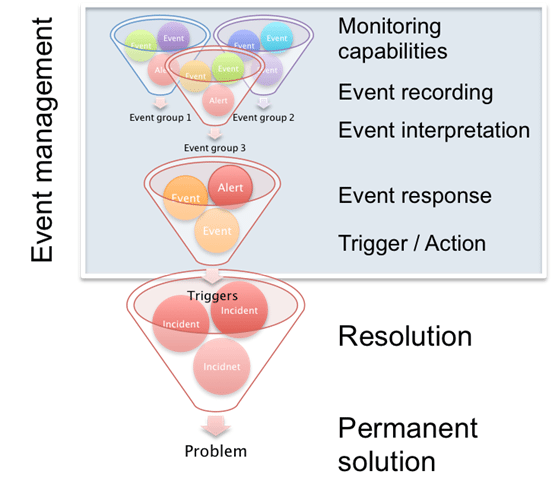
An event in ITIL is a product of a change to an IT system or environment. Organizations must monitor these events for problems or incidents. After these events have been identified and monitored, quickly take rectification procedures or processes if need be.
This is where event management comes in, it provides organizations with a holistic and proactive approach to ITSM. Below is a clue to what the interviewer expects from you when they ask the above question.
Expected answer when asked “What do you mean by Event Management in ITIL?” in an interview.
Event management involves a series of processes that ensures that the events following an improvement or change to IT infrastructure are identified and monitored. This is done seamlessly so that normal operations are not disturbed while ‘exceptional events’ or ‘exception conditions’ are being detected.
All events can be classified into three categories:
- Information: This refers to a successful task such as an email received by the participant or user login.
- Warning: This shows a service or device when it’s reaching a threshold limit, for instance, a server reaching its memory usage limit or a scheduled backup not running
- Exception: This refers to an error reported when a component of the system acts abnormally, for example, a backup failing or a server going down.
Event management metrics can be obtained at the Service Design Stage. These metrics will help organizations during CI determine which events need to be generated and answer the question ‘How will they be generated?’ The main event management metrics displays the:
- Number and percentage of events caused by existing problems or known errors
- Number and percentage of events that required human intervention
- Number and percentage of events that resulted in incidents or changes
- Number of events by category
- Number of events by the significance
Q50. What is the difference between a process and a project?
There are many similarities between a project and a process, which is why many think they refer to the same thing. This question is designed to check if you’re aware of the differences and fully understand what each term means. Some of the significant differences you should take note of have been discussed below.
Expected answer when asked, “What is the difference between a process and a project?” in an interview.
Although the terms “process” and “project” are often interchangeable, they are not the same. Some of the significant differences between both terms are:
- No. of times repeated: One distinctive factor of the two is how often you can repeat them. Organizations create processes to use repeatedly, whereas projects are deployed and implemented once. For an organization to use a project template for a second time, it would require a warrant process status.
- Purpose: The purpose for creating and implementing a project is different from that of a process. A project’s primary goal is to succeed, and companies should complete it within a time frame and budget. In contrast, the objective of the process revolves around optimizing an existing process. The focus is not on creating it—a standard process template is already available—but refining it.
- Risk: Projects require a lot of planning and strategizing because of the considerable risk involved since it’s a one-time endeavor. On the other hand, there is minimal risk attached to processes.
Note that project and process are closely related such that you can find processes and projects within each other. It’s not wrong to say a project itself is a process.
Q51. What are the responsibilities of the ITIL Service Desk?
The service desk is one of the most critical core operations that require daily monitoring. If you’re just getting started with your IT department and want to set up a service desk for the first time, the process can be frightening, especially if your objective is to follow ITIL® best practices from the start.
Some of the responsibilities of an ITIL Service Desk include:
- Incident management reporting
- Examining incidents
- Resolving the incident
- Incident prioritization, categorization, and logging
The availability of all services delivered and supported by the IT department is ensured through service desks. While a well-designed service desk might help your company run more efficiently, one that is badly implemented can hurt your bottom line.
Some other important objectives of the service desk include:
- In the event of a disruption, restore “normal service operation” as soon as possible.
- Take initiatives to raise user knowledge of current IT concerns and encourage proper usage of IT services, components, and resources.
- Assisting other ITSM processes and functions by escalating incidents and requests according to stated procedures and keeping an open line of communication.
Q52. Explain the 4 Ps needed for ITIL Service Management.
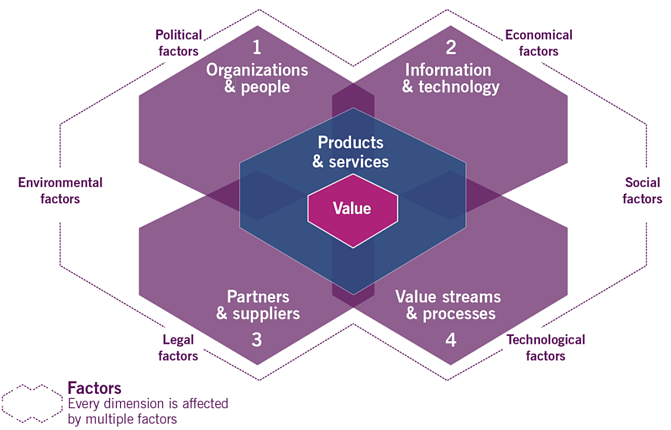
The 4 Ps for the ITIL Service Management are:
- People: All IT services’ development, deployment, and operation are all dependent on people. A good relationship between a service provider and its consumers is built on the customer having a cost-effective service that fits their demands and performs well.
Without a clear knowledge of the customer’s desired outcomes or the value they hope to derive from the service, there’s a good possibility that the developed service will fall short of their expectations, wasting resources and possibilities for the company. To ensure that the expectations of the clients are met, the IT professionals involved in the design and execution of the service must be appropriately trained and equipped.
- Products: The term “products” refers to both the service and the technology that underpins it. The importance of selecting the correct technology in the pursuit of a balance of usefulness, performance, and affordability cannot be understated. While the features derived from customer requirements will be the primary driving force, the service must be supported by the proper environment, infrastructure, applications, interfaces, and data sources. And, like a jigsaw puzzle, how these are put together will be determined by the architecture that will guide the technological design efforts.
- Processes: Processes convert one or more inputs into predefined outputs. They cover all of the roles, responsibilities, tools, and management controls needed to produce the outputs consistently. A mature process is one in which adequate controls and enablers have been implemented to ensure that the process activities run smoothly.
Whether automated or manual, it’s critical to build appropriate processes to support new services during design to ensure that the relevant process activities and responsibilities are in place once the services go live—whether it’s access or request fulfillment, change or deployment, inventory or payment.
- Partners: In this age of outsourcing, managed services, and cloud computing, partners have become critical to IT service delivery. Any service provider would typically purchase service components from an approved supplier, and the underlying contract will typically include terms, conditions, and targets to support the service levels agreed upon with the client.
It is critical to establish a good working relationship with any IT service provider, whether it is a strategic, tactical, operational, or commodity supplier because the IT service provider will never meet the needs of the business without the assistance of a partner who understands the organization’s needs.
Q53. What is the RACI model?
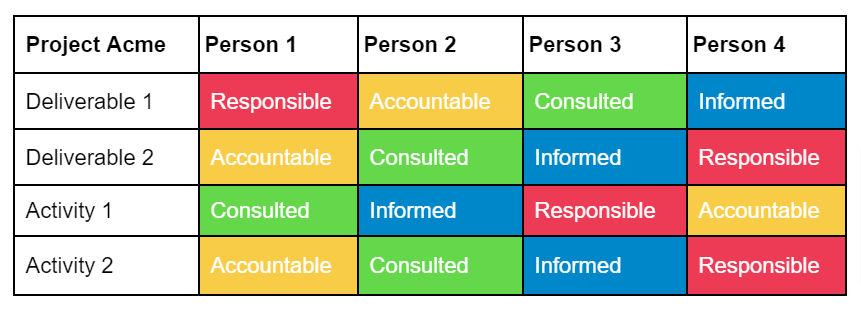
The RACI model is a system for defining project responsibilities and roles. This method eliminates any misunderstandings about obligations and roles. RACI stands for “responsible, accountable, consultative, and informed.” It emphasizes the various levels of accountability that a stakeholder has for a certain task or delivery.
The RACI matrix roles indicate the level of involvement of a stakeholder or team member in a given task.
- Responsible: Individuals who perform the work required to achieve a task, each of whom is assigned responsibility or function.
- Accountable: The person who is responsible for ensuring that the task was completed correctly and fully.
- Consulted: Individuals or groups who are consulted for a task and supply project information via two-way contact.
- Informed: People who are brought up to date on the task’s progress, usually through one-way communication.
Q54. What is the purpose of Configuration Management?
Regardless of your ITSM framework, configuration management aims to achieve the following objectives for IT projects:
- Defining, identifying, and comprehending asset configuration dependencies. Any configuration change has the potential to impact service performance and security.
- Keeping accurate configuration information across a variety of infrastructure assets in various states. IT teams can keep the IT infrastructure in an ideal state for each phase of the SDLC lifecycle, such as development, test, production, and release, with accurate configuration state information.
- Assisting with informed decision-making in areas like change authorization, release management, and issue resolution, as well as other ITSM framework service functions.
- Maintaining control over how configurations are updated and changed. In a DevOps environment, these controls include Infrastructure as a Code (IaaC) and Configuration as a Code (CaaC) techniques. Ensure that proper approvals for releases into controlled settings are followed.
- Keeping track of configuration information and modifications that could jeopardize the integrity of CIs. The configuration management process should be audited to ensure that the relevant security and compliance rules are followed.
Q55. What is the difference between proactive and reactive problem management?
The goal of reactive problem management is to solve problems as a result of one or more incidents.
Proactive problem management is focused on finding and resolving problems and recognizing faults before they cause new incidents.
Both approaches are critical for establishing a holistic and thorough approach to addressing the underlying issues that negatively impact IT services, but most support teams turn to the reactive approach first. Balancing the two techniques should be ingrained in your organization’s culture and one of the leadership’s top priorities.
Q56. What is the difference between an Incident and a Problem?

An incident” and a “problem” may be the same things on the surface. In layman’s terms, either word can be used to describe a scenario that is having a negative influence on the organization. However, in IT, the two words are distinct and must be addressed and managed as such, with distinct aims in mind.
An incident, in its most basic sense, is a single, unrelated event. Users frequently create an IT help desk ticket for incidents that they anticipate to be fixed immediately. Problem Management attempts to prevent incidents by identifying the fundamental cause of problems. Many occurrences can occur as a result of a problem.
The distinction between an incident and a problem is critical for business owners and managers outside of IT. While the terminology may appear to be interchangeable, communicating explicitly in IT support jargon will help to prevent confusion and irritation. If you report an incident to IT support when it’s a larger issue, the underlying fundamental cause may go ignored, resulting in additional issues.
Q57. What is a ‘change request’ in ITIL?
A change request is a written request for a change to a product or system.
In project management, a change request occurs when a client requests an addition or modification to the project’s agreed-upon deliverables. Among other things, such a change could entail the inclusion of a new feature, customization, or service extension.
Because change requests go outside the boundaries of the agreement, the client is usually responsible for the additional resources required to meet them.
One of the more difficult components of change management is making sure that all details are adequately explained and that everyone understands what is required. It is easier to determine whether a change request must be made when there is explicit and extensive documentation.
Change requests can also come from within the company. Patching and software and hardware upgrades are just a few of the steps that might be requested as part of an internal change request.
Once a change request has been submitted, the change control process should be followed to ensure that the request is fulfilled quickly and without wasting resources.
Q58. What is a ‘service request’?
A service request refers to a request usually made by the user or user’s representative to initiate a start of an agreed-upon service activity—a standard aspect of service delivery. The requests aren’t valid during service degradation (incidents) or breakdown.
User-initiated service requests are handled efficiently and effectively by the service request management process to promote the pre-defined quality of service. The service request management practice utilizes automation and tracking tools in form of procedures and processes to increase its efficiency. For effectively service request management, organizations must follow the following standards:
• Automation and standardization of service requests and their fulfillment should be done to the maximum extent practicable.
• There should be well-defined specifications as to which service requests can be fulfilled without extra approvals to speed up the process.
• Delivery timelines and costs should be realistic based on the company’s capacity to meet users’ expectations.
• Businesses should regularly look for improvement areas and implement them to take advantage of automation and reduce fulfillment times.
Q59. What is the ITIL Life-cycle Model for services?
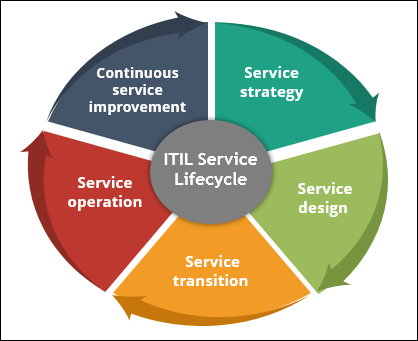
IT services, like processes and products, have lifecycles. Services lifecycles are described in ITIL service management best practices to describe the process of how services are begun and maintained. Services cannot be implemented and managed with maximum efficiency and efficacy without these ITIL lifecycles. For IT services to perform properly, it is critical to follow the ITIL lifecycle principles.
Service Strategy.
Service Strategy is the first stage of the ITIL lifecycle. As previously stated, the Service Strategy stage lies at the heart of the ITIL service lifecycle. A consistent service plan is required to improve service management in a service provider business. The organization’s business objectives and strategy should be in line with the service provider’s long-term vision.
They should be the organization’s lifeblood. IT strategy, on the other hand, should serve the business objectives of an IT service provider organization. Because this is the organization’s most important component. These IT service plans are part of the ITIL Lifecycle of Service Management’s initial level. The Service Strategy stage outlines the policies and objectives for managing IT services under the organization’s business goals.
Service Design
Service Design is the second stage of the ITIL lifecycle for services. The strategies developed in the Service Strategy stage are put into action in the Service Design step. To improve service management, services and processes are established and strategies are implemented. This is the stage of the ITIL lifecycle in IT services that is both productive and creative.
Owners of service businesses can use this tool to create services that will delight their clients. It is also here that meticulous attention to detail, as well as foresight, are critical to success. The right team must be assigned to this stage of the ITIL services lifecycle implementation.
Service Transition
Service Transition is the third stage of the ITIL lifecycle for services. Services and procedures established in the Service Design stage are moved to a live environment in the Service Transition stage. This stage entails preparing services and processes for use in the real world.
It also includes testing before going live in the real world. Customers are provided with services and processes after this level. It’s critical to test all possible scenarios that could occur in the real world. Its purpose is to ensure that there are no problems when clients begin to utilize the service. In this step of the ITIL lifecycle, thoroughness is crucial.
Service Operation
Service Operation is the fourth stage of the service lifecycle. The Service Operation lifecycle stage is where you manage services and processes that have been migrated to a live environment for client use. The service owner is responsible for the service’s quality.
He must make certain that customers are happy with the services he provides. Any severe difficulties must be reported as soon as they happen. Customers’ service level agreements bind the firm at this point. As a result, the service provider must ensure that the organization abides by the contract.
Continual Service Improvement
The Continual Service Improvement stage of the ITIL lifecycle for services is the final stage. Based on predetermined aims, services and procedures are planned, devised, and implemented. Better service management necessitates ongoing service monitoring and control. This stage, like the others in the ITIL lifecycle, is linked to the Service Strategy stage.
To assess whether the service is performing optimally, key performance indicators must be in place, and the service owner must ensure that the service meets the strategic goals associated with the IT service. Once predefined goals and expectations have been met, new goals should be set, and service management should strive to meet them. Continual Service Improvement is the stage of the lifecycle where ongoing services and procedures are improved.
Q60. Name the ITIL Models commonly adopted by the organizations.

Organizations often employ the following ITIL models:
- Hewlett-Packard (HP ITSM Reference Model)
- IBM (IT Process Model)
- Microsoft MOF (Microsoft Operations Framework)

Q61. What is ISO/IEC 27002?

The ISO 27002 standard is a set of information security standards aimed at assisting organizations in implementing, maintaining, and improving their information security management.
Hundreds of potential controls and control mechanisms are specified in ISO 27002, which are supposed to be applied using the guidance provided in ISO 27001. The standard’s suggested controls are meant to address specific issues discovered through a formal risk assessment. The standard is also meant to serve as a roadmap for creating security standards and implementing effective security management practices.
The International Organization for Standardization (ISO) and the International Electrotechnical Commission (IEC) jointly publish ISO 27002. (IEC). ISO 27002 was first published in 2000 under the designation ISO/IEC 1779. It was revised in 2005 to coincide with the publication of ISO 27001. The two standards are meant to be used in conjunction with one another, with one complementing the other.
The standards are updated regularly to include references to other ISO/IEC security standards, such as ISO/IEC 27000 and ISO/IEC 27005, as well as information security best practices that have emerged since prior editions. These tasks involve selecting, implementing, and managing controls that are tailored to an organization’s specific information security risk environment.
Q62. Give some examples of web-based service desk tools.
The following are some examples of web-based service desk tools:
- BMC
- CA service desk
- Cloud Help Desk
- Oracle Service Cloud
- ServiceNow
- SolarWinds Web Help Desk
- Tivoli
Q63. Which ITIL processes belong to Service Strategy?
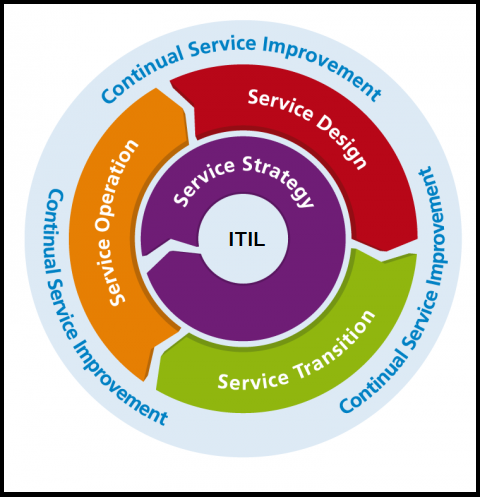
The following ITIL processes are part of the Service Strategy category:
Strategy management
Strategic management entails the continuous planning, monitoring, analysis, and evaluation of all requirements that a business must meet to achieve its goals and objectives. Changes in the business climate will need businesses to reevaluate their success methods regularly.
The main objective of the strategic management process is to assess business conditions, create strategies for improvement, implement them, and evaluate the effectiveness of the management methods.
Service portfolio management
The governance of a service portfolio is called service portfolio management. The technique allows a service provider to manage their investments across the service lifecycle by considering the business value delivered by each service.
Service portfolio management allows a service provider to govern the admission of any service into the service portfolio by tracking any service investment throughout its lifecycle, from creation to delivery and retirement.
Financial management
Financial management for IT services comprises financial models and techniques that allow us to calculate the services’ worth. It covers fundamental topics including money, accounting, and budgeting. An organization’s overall financial management rules and practices are applied consistently across all of its departments. This frequently results in the creation of the second level of financial management that is tailored to the department’s governance requirements.
Financial management for IT services helps and improves the service provider’s decision-making ability, allowing them to be more agile and effective. Simultaneously, it makes sure that they are financially compliant and flexible.
Demand management
ITIL demand management assists a company in determining and forecasting client demand for services. Every company has cyclical behavior. The goal of demand management, according to ITIL, is to understand, anticipate, and impact consumer demand for services.
Business relationship management
The ITIL framework’s Business Relationship Management (BRM) section deals with anticipating current and future customer needs. Apart from BRM, it is primarily defined during the Service strategy phase, which includes the following major processes:
• IT service portfolio management
• IT service financial management
• IT service demand management
• IT service strategy management
In summary, BRM optimizes the value of service delivery for the customer, enhancing the client-organization connection.
Q64. Which ITIL processes belong to Service Design?
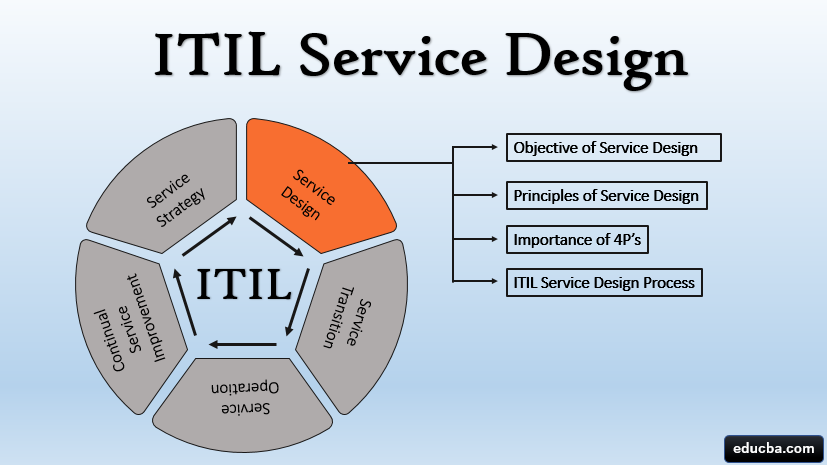
The following ITIL processes are part of the Service Design category:
Supplier Management
In-Service Management, Supplier Management is crucial. It oversees third-party suppliers, albeit some may be internal, as well as the services they give to the client. The goal is to ensure quality, consistency, and value for money, or to put it another way, to get the best deal possible.
The Supplier Strategy, which is input from the Service Strategy and associated policy, drives the activities and tasks in this process.
When implementing the policy, it is critical to building a Supplier and Contract Database (SCD) that allows for consistent efficiency and effectiveness. The SCD, in an ideal world, would be integrated into the overall Configuration Management System (CMS) or Service Knowledge Management System (SKMS). Contracts, their lengths, the services offered by providers, and any associated Configuration Items should all be stored in these repositories (CIs).
Service Level Management
The ITIL Service Delivery area has five components, one of which is Service Level Management (SLM). Within the ITIL framework, it is likely the most significant set of processes. Services are identified, service levels required to support business operations are agreed upon, Service Level Agreements (SLAs) and Operational Level Agreements (OLAs) are produced to satisfy the agreements, and service charges are developed using SLM methods.
IT personnel may more precisely and cost-effectively provide designated levels of service to the business by implementing Service Level Management methods. The processes guarantee that both the business and IT departments are aware of their roles and responsibilities and that the business units are empowered.
In the end, business units, not IT, must justify the levels of service required to support business processes to top management. Furthermore, the built-in continuous improvement methods ensure that when business needs evolve, so do the supporting IT services.
Service Catalog Management
The Service Catalog is a decision-making tool for service portfolio management. It shows how service assets, services, and business outcomes are linked. It also indicates a service’s need and demonstrates how the service provider will meet it.
The goal of the service catalog management process is to supply and maintain a single source of consistent information on all operational and upcoming services, as well as to make it broadly accessible to those who are permitted to access it.
IT Service Continuity Management
IT Service Continuity Management (ITSCM), which is part of the Service Design lifecycle, controls risk that could have a significant impact on IT services. By minimizing the risk of catastrophic events to an acceptable level and planning for IT service recovery, ITSCM ensures that the IT service provider can always provide minimum agreed Service Levels.
The ITSCM process is delivered by UCSF IT in collaboration with the Campus and Medical Center Emergency Management Departments, following each organization’s Business Continuity Plan.
Information Security Management
Information security refers to the activities that are involved in preventing information and infrastructure assets from being misused, lost, leaked, or damaged. Within the corporate governance framework, information security management (ISM) is a governance activity.
ISM refers to the controls that must be adopted by a company to ensure that risks are managed responsibly. The major goal of ISM in ITIL is to ensure that IT security is aligned with business security and that it meets the business’s requirements.
Design Coordination
The design coordination process is the final procedure in the ITIL service design stage of the ITIL Lifecycle for services. It’s a new addition to the revised ITIL V3 version, and it’s a useful aspect of service design.
The primary goal of design coordination is to ensure that the design stage’s objectives are met under the requirements. Its goal is to bring all of the service design activities, procedures, and resources together in one place.
Capacity Management
The practice of right-sizing IT resources to meet current and future needs is known as capacity management. It’s also one of ITIL’s five service delivery areas. Capacity management should be proactive rather than reactive. Those that excel at capacity management ensure that business and service requirements are satisfied with the least amount of IT resources possible.
Availability Management
The purpose of Availability Management is to ensure that the degree of service availability supplied in all services meets or exceeds the business’s current and future agreed-upon needs while remaining cost-effective. One of the most important aspects of a service’s warranty is its availability. If a service does not provide the requisite levels of availability, the business will not receive the value that was promised. The service’s utility cannot be accessed if it is not available. The activity of the availability management process spans the entire service life.
Q65. Which ITIL processes belong to Service Transition?
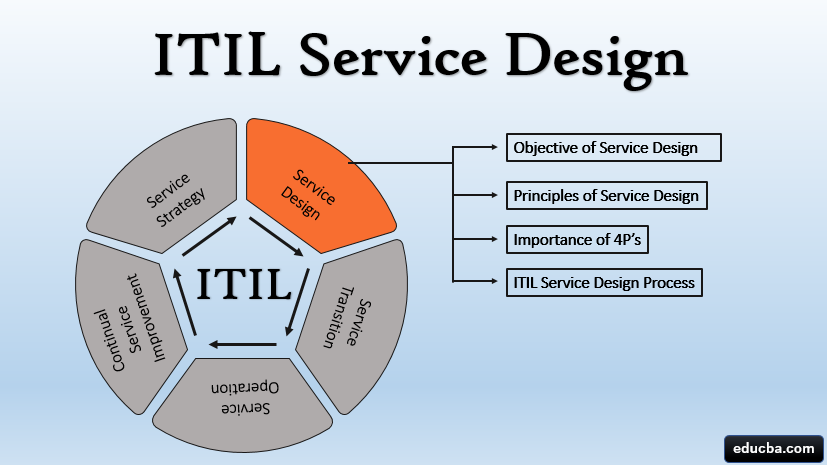
The following ITIL processes are part of Service Transition:
Transition Planning and Support
Transition planning and support refers to the process of planning and coordinating resources to meet the Service Design’s specifications. Through this approach, risks and difficulties are efficiently controlled. Transition Planning and support are comprised of a variety of tasks, including:
- • Create a transition strategy – This strategy outlines the approach to Service Transition as well as resource allocation.
- • Prepare Service Transition – This includes analyzing and accepting input from the other Lifecycle phases as well as other inputs such as identifying, tracking, and preparing Change Requests (RFCs).
- • Plan and organize Service Transition – An individual plan outlines the actions and tasks involved in deploying a release across various environments (Test and Live).
- • Assistance – Service Transition provides guidance and assistance to all parties. Stakeholders are communicated with and informed on processes, supporting systems, and tools by the Planning and Support team.
Service Transition efforts are baselined and tracked so that actual results may be compared.
Validation and Testing
One of the primary processes in the ITIL Framework’s Service Transition module is service validation and testing. It’s a method for actively maintaining test environments and ensuring that developed releases satisfy customer expectations.
The ITIL Service Validation and Testing Process also verifies and ensures that after the new services are deployed, IT operations will be able to support them.
The main goal of the ITIL Service Validation and Testing Process is to make sure that created releases and the services that result match customer expectations in terms of quality and value.
This procedure also assures that the IT operations staff will be able to support the new service to its maximum potential. The Service Validation and Testing Process also aids in the elimination of any mistakes discovered during the early stages of service operation.
• Plan and implement a well-structured validation and testing strategy that will give evidence that the service will satisfy business requirements and meet agreed-upon service level targets.
• Ensure that a new release is of high quality (for both services and components).
• Identify and eliminate risks, hazards, and errors during the Service Transition Stage.
Service Asset and Configuration Management

SACM (Service Asset and Configuration Management) is the process of correctly planning, managing, reporting, and auditing the relationships and attributes of all of these components across all of your infrastructure’s services. SACM is the result of the interaction of two key processes:
- • Asset management, which is concerned with the assets used to provide IT services.
- • Configuration management, which keeps track of the configurations and relationships among the many components (configuration items or CIs) that make up your various IT services.
SACM, according to ITIL, is the process that ensures that the assets needed to offer services are appropriately controlled and that accurate and reliable information about those assets is available when and when it is needed. This information comprises the configuration of the assets as well as the relationships between them.
This crucial procedure applies throughout the entire service lifecycle. SACM is critical to the health of both your services and your whole IT company, and it’s one of the first ITIL procedures that top IT companies employ.
SACM is primarily concerned with ensuring that you can identify and control all assets across your infrastructure, as well as manage their integrity through effective recording, reporting, and auditing.
The SACM process aims to
- Assist IT organizations with the identification, monitoring, and management of their assets throughout their lifecycle.
- Ensure all the services and other CIs such as components, baselines, versions with their relationships and properties are located, controlled, recorded, audited, and verified.
- Ensure that only authorized components and modifications are employed throughout the service lifecycle by working with the change management process.
- Ensure the integrity of the configurations required to control the services and CIs by developing an effective and comprehensive configuration management system.
- Record and keep up-to-date configuration information about the past, projected, and present states of service and other CIs.
- Provide appropriate personnel with accurate configuration information allowing them to make critical decisions, such as resolving incidents and authorizing changes that promote efficient service management operations.
Release and Deployment Management
The Release and Deployment Management phase of ITIL is dedicated to ensuring that your releases are delivered efficiently and successfully into production. The purpose of the Release and Deployment Management process, according to ITIL, is to plan, schedule, and control the build, test, and deployment of releases, as well as to deliver new functionality required by the business while maintaining the integrity of existing services.
The Release and Deployment Management process is divided into five stages:
Phase 1: Release and deployment planning
The point is to clearly define a set of guidelines for both what a release will include and how you will deploy it into production. A well-thought-out release and deployment plan is just one component of your overall Service Transition plan — but the point is to clearly define a set of guidelines for both what a release will include and how you will deploy it into production. As part of the Change Management process, the release and deployment strategy is then approved.
Change management normally authorizes the planning process for a release to begin at the start of the release and deployment-planning phase. Typically, the plan addresses:
- What changes the release will include
- Who will be affected or impacted by the release?
- What risk the release may introduce, if any
- The audience for the release (i.e., what users, customers, organizations will be impacted)
- A clear chain of approval, clarifying which stakeholders may authorize the change request at every stage of the release
- Ownership, defining the team that is ultimately responsible for the release.
- Deployment schedule and strategy
Building and test plans are frequently created at this point, clearly laying out essential details such as design specifications, testing processes, building, and testing deadlines, and even pass/fail criteria for each deployment phase. Optionally, a test deployment could be scheduled at this time.
Phase 2: Release building and testing
After a plan has been established and authorized by change management, the responsible teams must construct and test the release, which includes both software and documentation, as well as any other elements specified in the release plan.
Documentation is often prepared at the start of this process to ensure that developers can construct the release package as precisely and rapidly as possible — and accurate records should be kept throughout the build process so that the build process may be repeated if necessary.
Most firms have strict procedures in place, and some even give standard templates for putting together a complete release package. At every step of the journey, be sure you’re using and following these.
From testing all input CIs to testing and rehearsing the services before they are deployed live, testing occurs throughout the process.
Here are a few things to keep in mind throughout the way:
• Pilots are a terrific approach to find and fix any problems with a service before it’s rolled out to the complete target audience. • Some teams also choose to hold a rehearsal, effectively “practicing” as much of a service rollout as feasible just before a deployment is scheduled, which can significantly reduce risk.
Phase 3: Deployment
Beginning when change management permits the release package to be deployed to the target environments, this phase sees the release package deployed to the live environment. Handoff to service operations and early-life support completes the deployment phase.
ITIL recommends doing a lot of planning and preparation ahead of time, such as validating that the target group is ready for the deployment, identifying and attempting to minimize any potential risks or disruptions, and describing how each component of the release will be distributed in order (like financial assets, processes, and materials, the actual service release, etc.)
It’s vital to check that a release is working well for all stakeholders once it’s been deployed, and to fix or back out the release as needed if major issues develop.
After confirming that the release is working as expected, ITIL recommends a two-stage transition to service operations for the new or updated service. A formal notification that the service is now live (at the start of early life support, or ELS) should be provided first, followed by a formal notification that the service is fully operating and SLAs are being fully enforced afterward.
Phase 4: Reviewing and closing a deployment
It’s time to examine and learn from the entire process once the release has been delivered. Feedback is received, and performance goals are evaluated, with the outcomes being reviewed and shared by all parties involved.
Reviews should be thorough and meticulous, ensuring that all quality criteria have been met, that sufficient knowledge transfer and training has taken place and that any known problems, repairs, or changes have been properly documented. A comprehensive Post Implementation Review, or PIR, should also be conducted by change management.
Support for a deployment isn’t regarded as “closed” or “finished” until it’s properly transferred to Operations.
Change Management
ITIL Change management enables firms to implement new changes with minimal downtime and interruption. ITIL change management covers change evaluation, planning, and approval and follows a standard operating procedure to avoid any unwanted interruptions.
The change management process acts as a gatekeeper, ensuring that the continuing Infrastructure and Operations are not jeopardized. Pre-release tasks like rollout, backout preparation, and change schedules are all part of change management. It conducts quality control checks to guarantee that change and release activities are carried out according to plan.
ITIL Change management’s key goal is to minimize risk and impact. Change management is in charge of approving any change that is to be implemented. While a new update is being implemented, it protects the production environment. The ITIL Change management process has the following goals.
- Communication and approval management
- Effective change planning with optimized resources
- Maintenance of current working state
- Reduction in number of incidents due to change execution
- Reduction of risk and impact
ITIL Change Management can be applied in the following scenarios:
Implementing a new data center
- Deploying a bug fix to a production environment
- Windows patch
- Replacing ERP service provider
- OS upgrade
Change Evaluation
Change evaluation is one of the primary activities in the ITIL best practice framework’s Service Transition Module. The Change Management process has already been discussed. This procedure could be viewed as an extension of Change Management.
When a business decides to make big changes to its existing infrastructure or services, the ITIL Change Evaluation Process comes into play. To lessen the likelihood of failure, this process is carried out independently for managing risks connected with large changes. Change management initiates and controls the change evaluation process, which is overseen by the Change Manager.
This process is intertwined with others, including Design Coordination, Transition Planning & Support, and a portion of Incident Management. The goal of change evaluation is to provide a consistent and systematic method for assessing a change’s performance in terms of its expected influence on the company, existing or prospective services, and current and future IT infrastructure.
Q66. Which ITIL processes belong to Service Operation?
The following ITIL processes are part of the Service Operation:
Service request fulfillment
Request fulfillment is the process of managing service requests throughout their lifecycle, from the time they are first raised until the time they are closed. Request fulfillment was added to ITIL V3 as a new process to have a specific process for handling service requests.
Previously, the incident management mechanism handled both requests and incidents. This was prompted by a clear distinction in ITIL V3 between incidents (service disruptions) and service requests (requests for services) (standard requests from users, e.g., password resets). The process of fulfilling requests has been overhauled.
Request fulfillment is divided into five sub-processes, each of which includes a thorough description of the actions and decision points involved. Request fulfillment features interfaces with incident management, for requests that are later diagnosed as incidents, and service transition, for requests that require change management engagement. ITIL request fulfillment is a service request model that provides certain agreed-upon actions that will be followed for a specific type or category of service request.
The concept of service request status information is also present in ITIL. This is a message that contains the current status of a service request and can be sent to the user who submitted it. The request fulfillment process often provides status information to users at various times during the lifespan of a service request.
Problem management
ITIL® problem management is a procedure for ensuring that only minor incidents arise from IT infrastructure operations by delving deep into incidents to determine the root causes and solutions, as well as reducing the severity of incidents through appropriate documentation of existing issues and the provision of workarounds.
A systematic technique to identifying the source of an occurrence and managing the life cycle of all problems is known as problem management. The purpose of the ITIL® problem management procedure is to reduce the severity of incidents and eliminate those that occur frequently. While ITIL® does not provide a specific technique for problem management, it does advocate three steps:
- ITIL problem identification
- ITIL problem control
- ITIL problem management error control
Reactive problem management addresses issues that are currently affecting users, whereas proactive problem management addresses issues that could become incidents in the future if left unaddressed.
A good problem management procedure can help IT service desk workers save time and effort by reducing the number of incident tickets they receive. This advantage has a cascade effect, resulting in a shorter mean time to repair (MTTR), improved customer satisfaction, a strong known error database, and lower IT service and problem costs. Furthermore, a firm that employs proactive problem management is likely to reap significant benefits from recognizing and resolving problems before they impact business operations.
Incident management
The practice of incident management seeks to reduce the negative impact of occurrences by resuming normal service operations as soon as possible.
The service desk, which is the single point of contact for all users dealing with IT, is usually tightly associated with incident management. When a service is disrupted or fails to achieve the promised performance during normal business hours, it’s critical to get it back up and running as soon as possible.
Any situation that has the potential to cause a breach or degradation of service should be met with a reaction that prevents the actual interruption.
Event management
Event Management guarantees that all CIs are constantly monitored and establishes a mechanism for categorizing these events so that appropriate action can be performed if necessary. The process owner for this procedure is the IT Operation Manager.
The following components of event management can be used:
- Configuration Items (CIs)
- Environment Conditions (e.g., fire and smoke detections)
- Normal activity (e.g., tracking the use of an application or performance of a server)
- Security
- Software license monitoring for usage to ensure legal license utilization and allocation
As mentioned below, there are two sorts of monitoring tools.
• Active monitoring tools keep an eye on CIs to see if they’re up and running. Any deviation from the normal course of business is reported to the appropriate team for action.
• Tools that detect and correlate operational alarms or messages generated by CIs are known as passive monitoring tools.
Access management
Access management collaborates closely with information security management to guarantee that the information security policy’s access provisions are followed. Access requests can be submitted as service requests and handled by the service desk, or they can be forwarded to a security group for processing.
Controlling access to programs or data is an important aspect of information security management. Access management is in charge of dealing with user requests for access.
This procedure comprises not only the control of usernames and passwords but also the formation of groups or roles with defined access privileges, as well as the control of access by defining group membership.
When a user’s status changes due to transfer, resignation, or termination, access management revokes permissions in addition to granting them. Additionally, access management should check the roles or groups used to limit access regularly to verify that only necessary rights are issued and that no rights conflicts exist between the roles or groups.
Q67. What is ITSCM?
The ITSCM (IT service continuity management) process is a vital component of the ITIL service delivery stage. This process carries out incident management, prediction, and prevention activities to ensure that service performance and availability are kept at the highest level even in the event of a disaster-level incident.
By putting in place effective standardized processes, ITSCM aims to reduce the business impact, expenses, and service downtime in case of the occurrence of an incident. Without a specific plan for IT continuity, incident recovery can be disrupted or delayed due to various reasons.
For example, in a scenario where an incident that requires urgent attention occurring 3 a.m., calling your specialist at that moment is not ideal. They might be alarmed by the magnitude of the incident. Also, your specialist may have lost contact with the code if they’ve spent the past weeks or months working on another project.
Alternatively, what if your specialist is a new member of your incident management team with limited experience? All these can be avoided with a proper ITSCM strategy in place.
Q68. What is ICT?
ICT, or Information and Communication Technology, is a term that refers to information, communication, and technology. Yes, these two terms do not always refer to the same item.
There isn’t a single definition for information and communication technology. However, the phrase can be applied to any networking components, applications, devices, or systems that enable you to connect to the digital world.
Businesses have had a lot of room to grow with the arrival of ICT, it is general information. Its service-oriented solutions can help organizations better serve their clients.
While ITIL is a set of rules to follow to help a business thrive, ICT may provide the necessary infrastructure. ITIL can assist you in planning and generating ideas to streamline processes, while ICT can assist you in locating the devices and apps needed to do so.
Many times, ITIL and ICT work in tandem to assist the organization succeed.
Q69. What is the Service Value System?
The Service Value System (SVS) explains the relationship between an organization’s operations and components, as well as how they work together to create value. It includes service management-related outputs, inputs, and elements. Demand and opportunity are inputs, while the value delivered by services and products is the output. The following is a list of the most important inputs:
• Possibilities: Ways to improve the organization or provide value to stakeholders
• Demand: Consumers’ desire for services and products (internal and external).
The SVS is made up of the following components, which are listed below:
- • Guiding Principles: Policies that an organization can follow at any time, regardless of changes in its management structure, nature of work, strategies, goals, or objectives.
- • Governance: This is the system or structure that allows an organization to direct its course.
- • Service Value Chain: This is a set of interconnected operations that assists firms in realizing the value and providing valuable services or goods to their consumers.
- • Practices: This refers to a set of organizational resources used to achieve a goal or complete a specific task.
- Continual Improvement: A collection of operations carried out by an organization to ensure that its performance is always improving and that it satisfies the expectations of its stakeholders.
Q70. What are the Guiding Principles in the Service Value System?
The following are the seven guiding principles:
- Collaborate and promote visibility
- Focus on value
- Keep it simple and practical
- Optimize and automate
- Progress interactively with feedback
- Start where you are
- Think and work holistically
Q71. Explain the objective of Supplier Management?
Supplier management encompasses all aspects of an organization’s supplier relationships, including the life cycle. This enables enterprises to maximize the value for money acquired from suppliers while also ensuring a consistent and consistent level of service delivery to the organization. The following are some of the goals of supplier management: • Create and maintain a supplier policy
• Negotiating and creating contracts with suppliers • Managing the supplier relationship • Managing the supplier contracts database • Ensuring that all contracts provide the best value for money spent.
Q72. What is the difference between Utility and Warranty?
Utility is the functionality that a product or service provides to suit a certain requirement. The utility is also known as “what the service does,” and it can be used to assess whether a service is “fit for purpose.”
A service must either support the consumer’s performance or remove the consumer’s constraints to be useful. Alternately, do both.
Warranty
- • A warranty ensures that a product or service will satisfy agreed-upon specifications.
- • Warranty is defined as “how the service operates” and is used to judge if a service is “fit for use.”
- • Warranties are frequently associated with service levels in the form of a “formal agreement, or a marketing message or brand image” linked with service users’ needs.
- • Availability of the service, its capacity, degrees of security, and continuity are all examples of warranty.
- • A service warranty is said to be fulfilled if all of the service’s defined and agreed-upon terms are met.
Both utility and warranty are vital for service since they assist create value by facilitating desired results.
Q73. What is Service Validation and Testing?
Service Validation and Testing is a phase of the Service Transition process that involves service testing. Service Validation and Testing ensures the integrity of newly produced IT services or updates, as well as that they meet business demands and design specifications. This procedure can be implemented at any point during the service life.
Q74. What are the process activities of Service Validation and Testing?
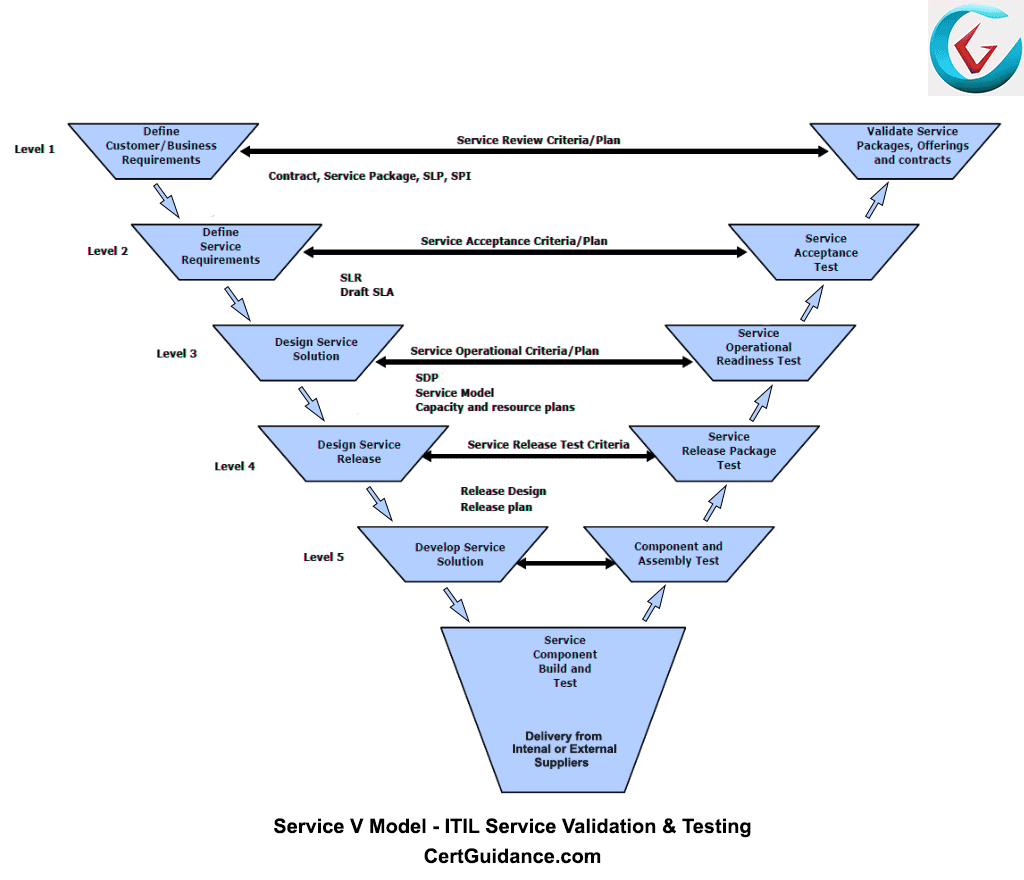
The following are the processes included in the Service Validation and Testing process:
- Validation and test management
- Test planning and designing
- Verifying the test plans and designs
- Preparing the test environment
- Performing the tests
- Evaluating the exit criteria and report
- Test clean up and closure
Q75. What are strategic/tactical/operational level changes?
The Strategic, Tactical, and Operational levels are the three levels where changes can be directed.
Business or Strategic changes
The ‘direction’ that a business is pursuing is referred to as business or strategic shifts. Senior managers would plan and implement any changes at this level. New strategic directions or shifts in existing strategic thinking are likely to have an impact on service delivery.
Service or Tactical changes
Changes to existing or new services that are required as a result of a shift in strategic direction are referred to as service or tactical changes. Although it may not be appropriate to link all service modifications to a strategic shift, it is a natural association to make.
Operational changes
Technology or service changes generate operational changes. For instance, if a service modification necessitates increased throughput, this is likely to trickle down to the operational level (faster machines, etc.) There may, however, be adjustments that are imposed on the organization (e.g., security upgrades, operating system upgrades, etc.)
Q76. Explain the objective of the Service Transition stage
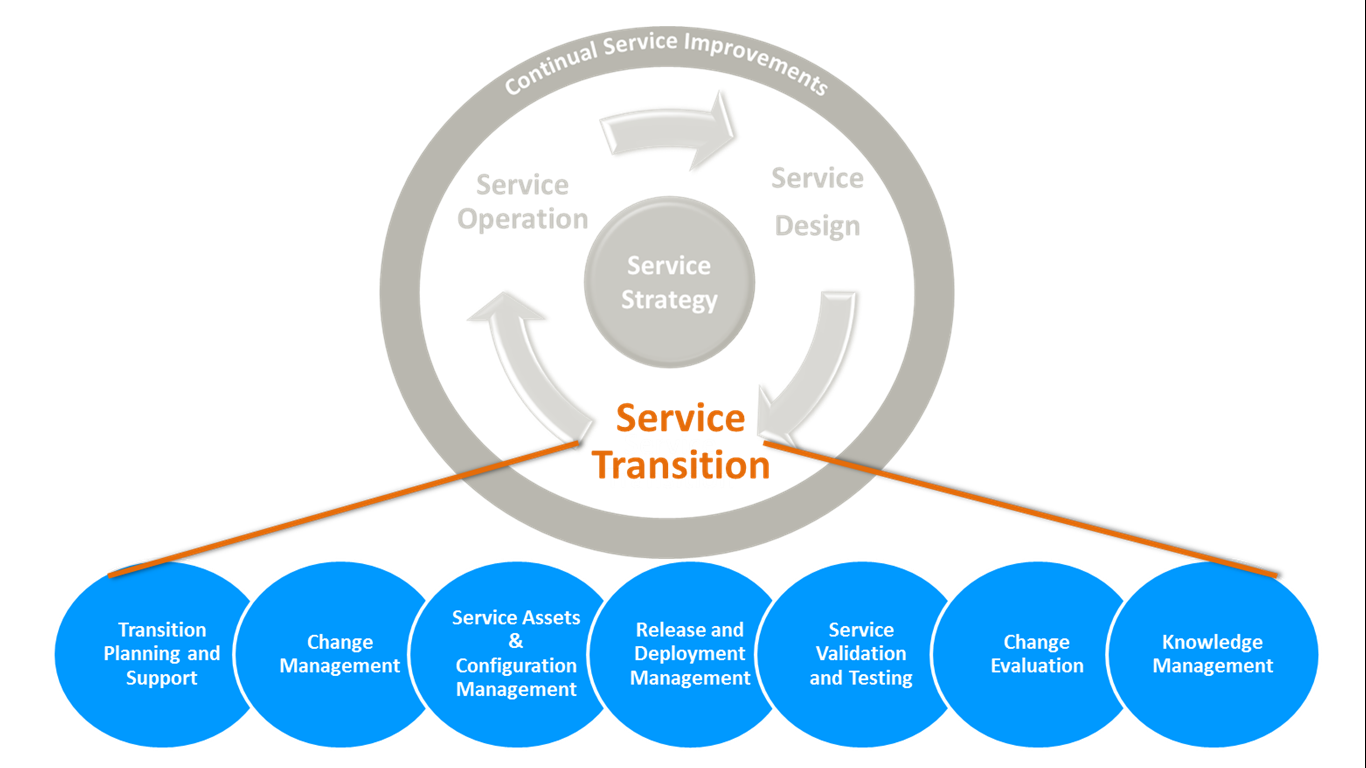
The primary goals of service transition are to efficiently and effectively plan and manage service changes.
• Managing the risks associated with new, modified, or canceled services.
• Deploy the service releases to environments that are capable of supporting them.
• Establish realistic expectations for the performance and use of new or modified services.
• Ensure that the service changes provide the anticipated value to the company.
• Provide the knowledge and information about services and service assets that are required.
Q77. Why do we need to ‘Engage’ as part of the Service Value Chain?
Understanding of stakeholder demands, transparency and strong connections with all stakeholders are all provided through the Engage activity. Customers’ requests are transformed into design requirements for the Design and Transition activity in this activity.
Q78. Explain the role of Service Operation in ITIL.
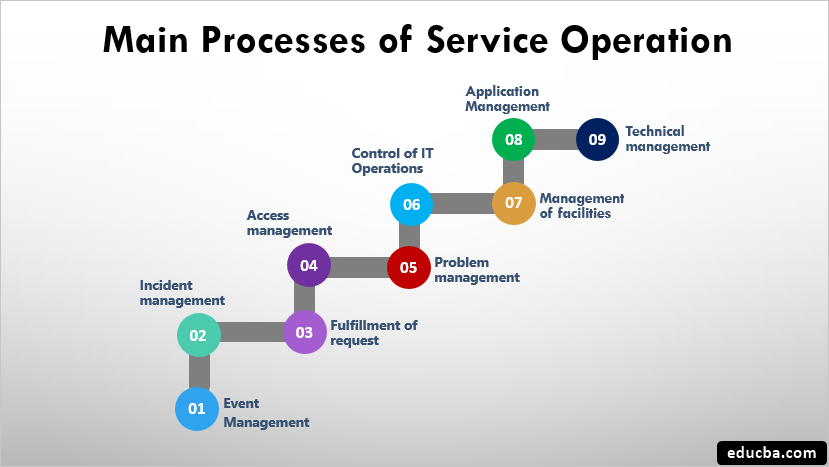
The day-to-day activities, processes, and infrastructure that is responsible for delivering value to the business through technology are referred to as service operations. Business customers have become entirely reliant on the capabilities that IT services enable, just as most people expect the lights to turn on at the flip of a switch.
The purpose of service operations is to keep day-to-day services running as smoothly as possible. When problems do arise, service operation principles mandate a reaction depending on the priorities of the business. Throughout the ITIL service lifecycle, feedback from service operations allows for continuous service improvement.
Service Operation’s primary responsibility is to assess the value of IT services.
• Serving as a point of contact (Service desk) between the organization and customers is another use of Service Operation in ITIL.
• Identifying actions in the service catalog that have yet to be completed.
• Ensuring that IT services are supplied sufficiently to all parties involved in the process.
Q79. Explain how Availability, Agreed Service Time, and Downtime are related.

The connection between the three phrases can be traced back to the percentage of service availability.
One of the most basic methods for calculating availability is based on two integers, which you may recall from your ITIL training. You decide how long the service should be offered during the reporting period. This is the agreed-upon time for service (AST). During that time, you track any downtime (DT). You subtract the downtime from the agreed-upon service time and convert the result to a percentage.
Q80. What is an IT asset?
“Any data, gadget, or other components of the environment that support information-related activities” is defined as an IT asset. Hardware (such as servers and switches), software (such as mission-critical applications and support systems), and secret information are all examples of assets.
The following are the different types of IT assets:
• IT hardware – this category is used to contain servers and desktops. Nowadays, IT hardware includes laptops, smartphones, and IoT (Internet of Things) devices.
• Virtual machines — although being software, virtual machines are used to replace hardware.
• Cloud services – because they run on hardware, cloud services are covered here. A demand for controlling the underlying hardware is common in private clouds.
• SaaS — many businesses treat Software-as-a-Service (SaaS) as software rather than a service.
• Digital information — digital assets, usually with licenses to utilize the data available for a fee.
Software refers to the programs that run on your computer.
Q81. What is Problem and Problem Management?
A problem is a situation that arises as a result of an unknown or known occurrence that leads to disruption in service. The word “Problem Management” refers to the process of identifying problems and devising workarounds or solutions for them. A robust problem management procedure is critical to ensure that the impact of problems is reduced and that such problems do not recur.
Problem management is the process of identifying and resolving the causes of problems with an IT service. It’s a crucial component of ITSM frameworks.
Problem management includes not just locating and resolving occurrences, but also recognizing and comprehending the underlying causes of those incidents, as well as determining the most effective way for eliminating those fundamental causes.
Furthermore, determining the reason has little benefit to an organization if it is a one-time process conducted by a compartmentalized team, therefore problem management should be ongoing and widespread across different teams, including IT, security, and software developers.
The incident may be over once the service is restored, but the problem will persist unless the underlying causes and contributing elements are addressed.
There are three stages to problem-solving:
- Error control
- Problem control
- Problem identification
Q82. What are the outcomes in ITIL?
An outcome is a result that one or more outputs have enabled for a stakeholder. These outcomes are aided by services. The terms “outputs” and “outcomes” are not interchangeable. A service provider creates products that help my customers reach their goals.
The results obtained after providing a service, following an activity, or doing an activity are referred to as outcomes. It comes in handy when comparing the actual outcomes to the desired outcome. Quantitative and qualitative results are the two types of outcomes. They can be calculated using input from customers and end-users of the service or product.
Q83. What is a Workaround?

A workaround, according to ITIL, is a temporary solution. Temporarily, workarounds restore service. ITIL doesn’t say how long “temporary” means; it merely says that a workaround doesn’t fix the problem’s core cause. “Temporary” can refer to any period ranging from a fraction of a second to fifteen years and beyond.
It’s not uncommon for an IT department to get into the habit of using a workaround frequently without ever exploring the fundamental cause. A “server reboot” is one way this is regularly seen.
Typically, there is a memory leak on the server, and the business has concluded that rather than pursuing the root cause of the memory leak, it is more practical to reboot the server regularly. This is good, especially when cost-effectiveness is a concern, but the business runs the danger of failing to address the core cause because the reboot does not address it.
To put it another way, it’s likely that implementing the interim repair, in this case, will result in the server rebooting back into the problem state.
Q84. What is BCP?
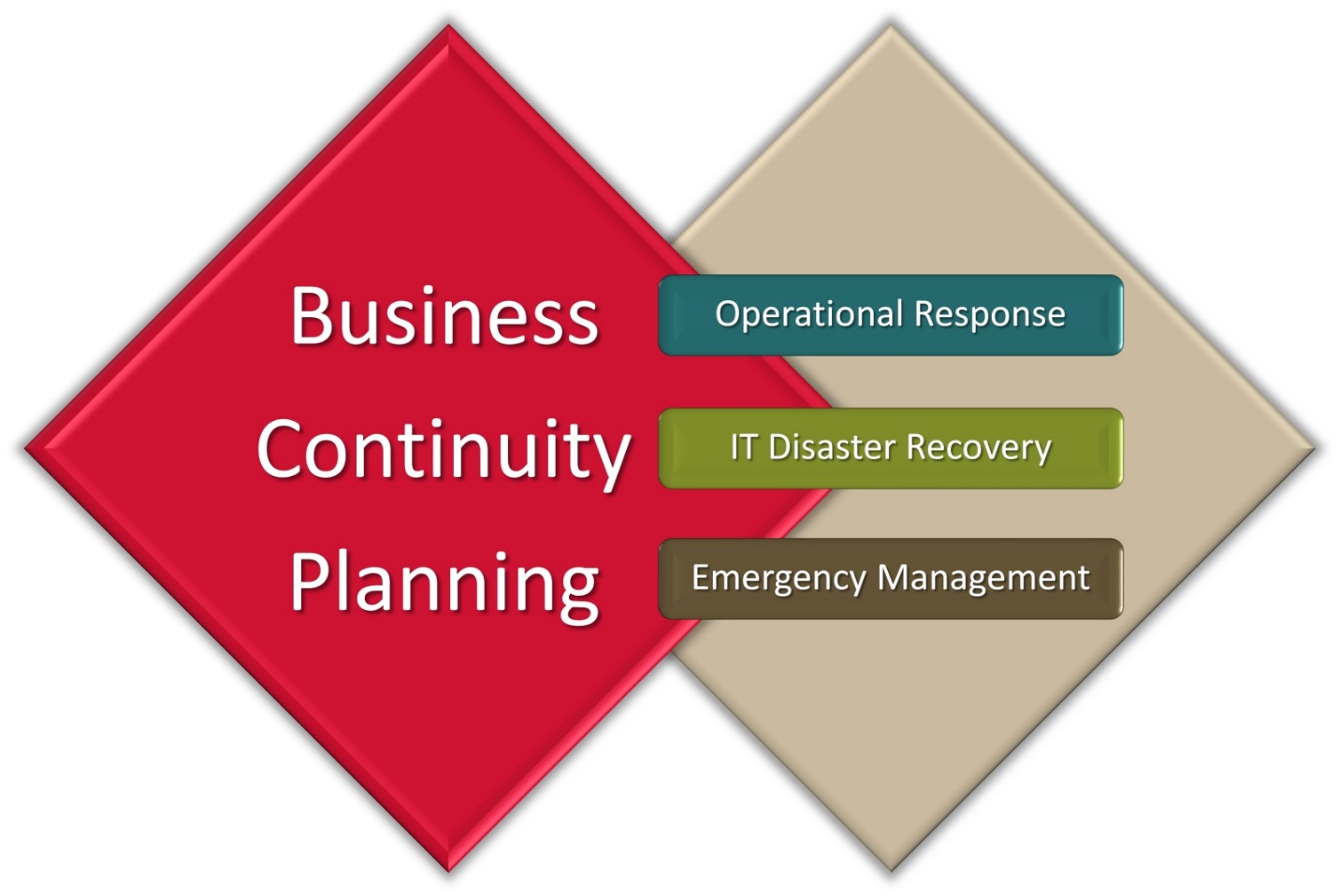
The process of developing a framework for preventing and recovering from potential risks to a corporation is known as business continuity planning (BCP). In the event of a crisis, the plan ensures that workers and assets are protected and that operations can resume rapidly.
BCP entails identifying and defining all risks that could have an impact on the company’s operations, making it a vital aspect of the risk management strategy. Natural disasters, such as fires, floods, or weather-related occurrences, as well as cyber-attacks, are potential threats. Once the risks have been identified, the plan should incorporate the following:
• Identifying how the risks would impact operations and putting in place protections and procedures to manage the risks
• Ensure that procedures work by testing them; • Review the process to ensure that it is up to date.
BCPs are an essential component of any business. Threats and disruptions result in a loss of revenue and an increase in expenditures, resulting in a decrease in profitability. Furthermore, businesses cannot rely solely on insurance because it does not cover all costs or clients who defect to the competition. It is usually planned ahead of time and involves key stakeholders and individuals.
Q85. What is Change Enablement?
Change Enablement (also known as Change Management) is the process of providing people with the information and skills they need to successfully adapt to new technology, method, or policy aimed at improving business outcomes.
Front-line users are the focus of Change Enablement. The Change Enablement process evaluates a company’s culture, history, individual workflows, and potential roadblocks to adopting new technologies.
Following the assessment, a tailored Change Enablement plan is developed and deployed in tandem with a new technology effort. The plan, which is led by a Change Enablement team, assists users in adopting new behaviors, abilities, and efficiency while avoiding the technical and emotional challenges that come with change. Individual users benefit from this targeted “enablement” approach since it helps them not only accept current change but also modify their thinking to welcome continuous change.
Q86. What does a Known Error mean in ITIL?

A problem with a documented root cause and a Workaround is referred to as a Known Error. The Problem Management method manages Known Errors throughout their existence. Each Known
Error is documented in a Known Error Record that is kept in the Known Error Database (KEDB). Problem Management is typically responsible for identifying Known Errors, but they can also be proposed by other Service Management disciplines, such as Incident Management, or by suppliers.
Q87. What is the Post Implementation Review?
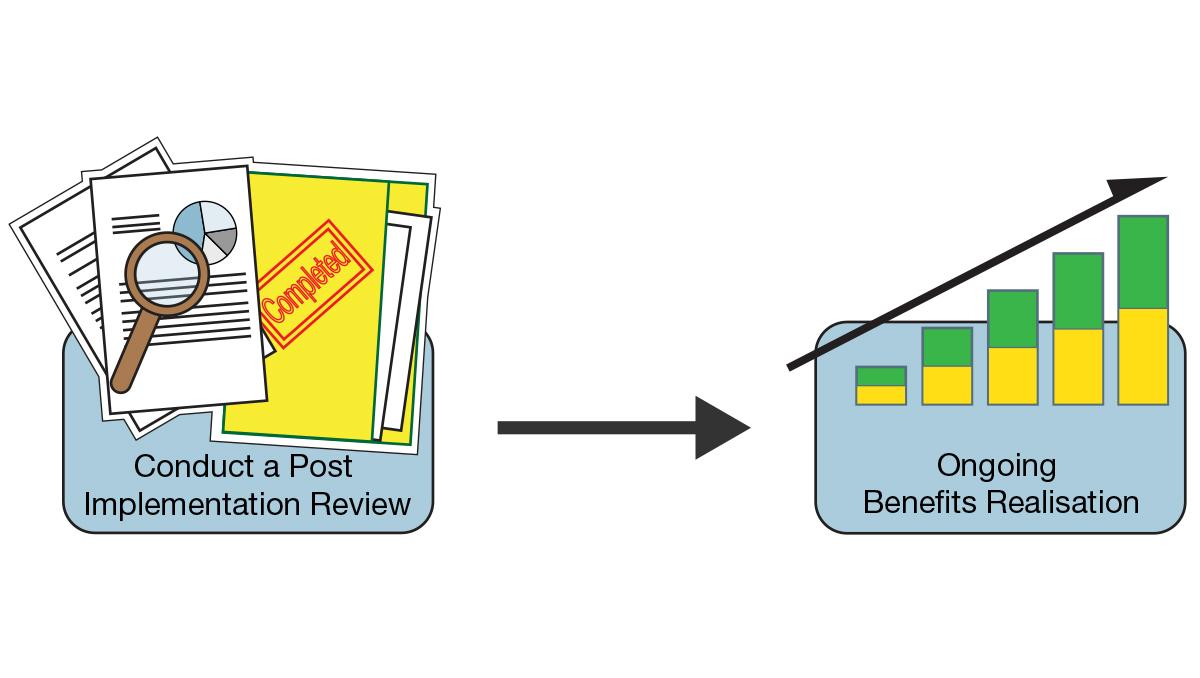
Post-implementation review is a procedure for ensuring the integrity of a problem’s final operational solution. PIL assesses and evaluates a change and its implementation to determine whether it was successful or not. PIL attempts to provide answers to questions such as:
- Did the change solve the problem it aims to address?
- In the case of failure, did the back-out plan work?
- Did the change impact the customers?
- Were resources allocated effectively through the process?
- Was the change implemented based on a budget and promptly?
Q88. Name some knowledge management systems related to ITIL.
- KEDB (Known Error Database): The KEDB is a database that saves data from the Known Error Record as part of the Problem Management process. The details of every known error are kept in the known error record.
- Capacity Management Information System (CMIS): The CMIS is in charge of gathering data and information about IT performance, capacity, and infrastructure usage. Data is collected regularly and stored in a single or more databases.
- AMIS (Availability Management Information System): The AMIS is a virtual repository system that stores all Availability Management data (typically across many physical sites).
Q89. Why do we need Relationship Management?
 The client and the IT service provider have a solid, good relationship thanks to business relationship management. This is an important relationship that should not be overlooked. As a result, many businesses hire a Business Relationship Manager.
The client and the IT service provider have a solid, good relationship thanks to business relationship management. This is an important relationship that should not be overlooked. As a result, many businesses hire a Business Relationship Manager.
The Business Relationship Manager (BRM) anticipates client demands both now and in the future. Essentially, the BRM ensures that IT services are appropriate and effective from the perspective of the consumer. This entails coordinating with strategic business partners such as IT, finance, HR, marketing, and legal. As a result, the client’s long-term relationship with the IT service provider is strengthened.
The goal of Relationship Management is to ensure that services and products are delivered seamlessly by appropriately managing the organization’s suppliers and their performance. It aids in the development and maintenance of a positive relationship between stakeholders and the company.
Q90. Why do we need Information Security Management Systems?
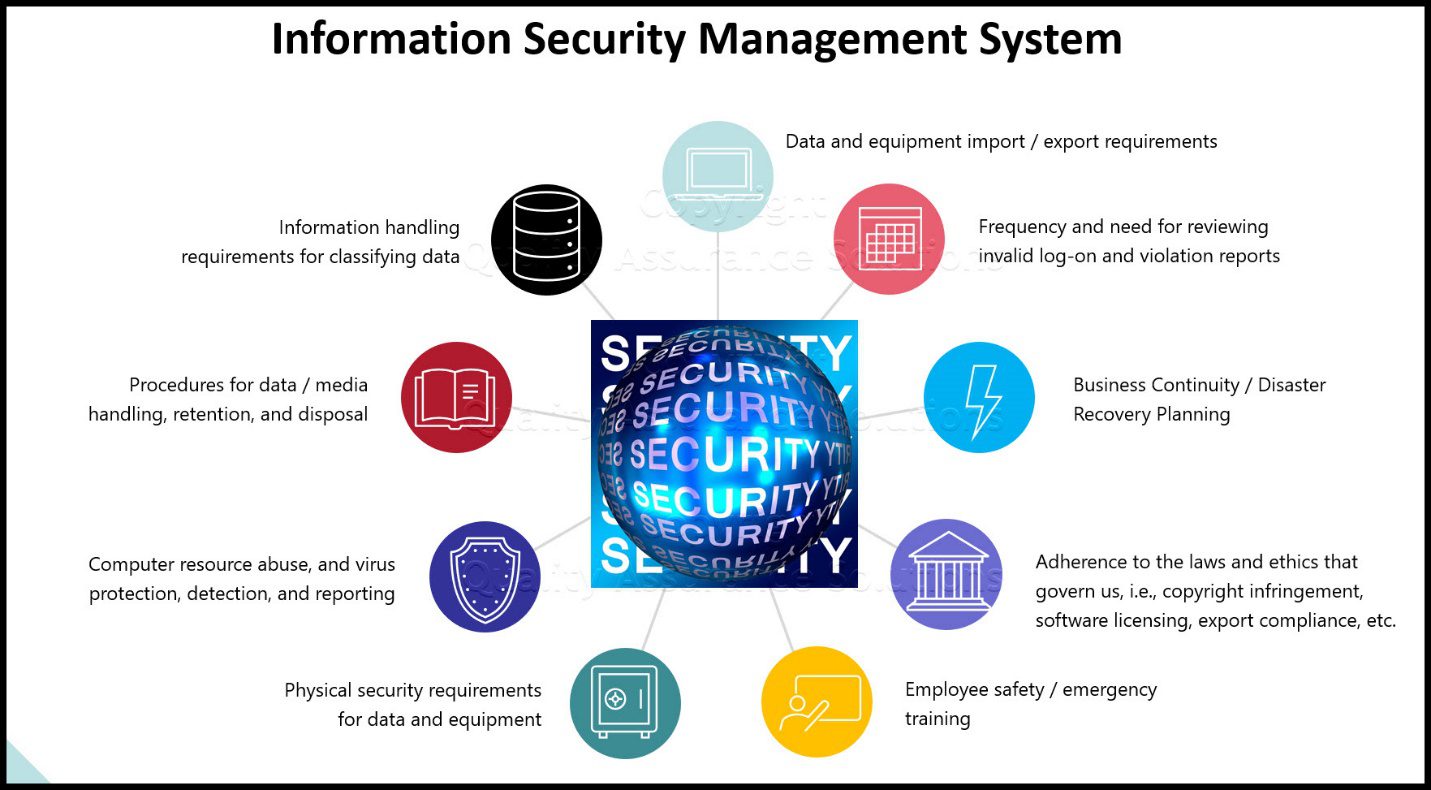
Information Security Management Systems (ISMS) is designed to ensure the integrity of data across all service management activities and services by aligning IT security with business objectives. These ensure the following: • Trustworthiness of business transactions and information exchanges.
• Information is safe, accurate, and comprehensive, with no risk of illegal access; information is released only to those who are meant, and information is easily accessible when needed.
Security management is also critical in ensuring that firms can avoid, withstand, and recover from disruptions or incidents.
Q91. What is the purpose of deployment management practice?
The deployment management practice is responsible for the introduction of processes, documentation, new or modified hardware, software, or any other component into live or testing environments. While DMP shares some similarities with change control and release management, the practice utilized a unique technique.
In some businesses, the term “deployment” only applies to software deployment, while in the case of the deployment of infrastructure, “provisioning” is used. However, in ITIL v4, “deployment is used as a reference to both types of deployments.
In the ITIL v4 framework, there are four types of deployment approaches. The most appropriate approach for the business depends on various factors such as the impact of the releases, service kind, quality, and requirement. Most businesses use a combination is these different approaches.
• Phased deployment: Deployment of new or improved components is targeted to a subset of the production environment, for example, users in a single country or office. And, the procedure can be repeated as often as needed for the process to be completed.
• Continuous delivery: Here, the integration, testing, and deployment of components are done based on the requirement. This allows customers to provide input regularly.
• Big bang deployment: The deployment of the new or updated component to all targets is done simultaneously. This type of deployment is usually adopted when the dependencies require the utilization of both the new and old components at the same time. For example, the previous version of some components may be incompatible with the updated database schema.
• Pull deployment: Here, the update or new software or component is deployed in a controlled repository, providing users with the freedom to whether to download it to their devices. The schedule of updates is controlled by the users and can be used alongside service request management providing users the component or software upon request.
Q92. What are the processes utilized by the Service Desk?
Multiple ITSM operations are frequently included in service desks. Service request management, incident management, knowledge management, self-service, and reporting, for example, are common ITSM operations covered by a service desk. Problem and change management processes are frequently inextricably linked.
Q93. How does the Incident Management system work?
The process of incident management is in charge of overseeing the life cycle of all incidents. Work on restoring normal operations or resolving a specific type of event are both part of incident management activities. The goal is for the IT staff to get service back up and running as soon as possible after a disruption, with an as little negative impact on the company as feasible.
Due to the increasing need for 24/7 service availability, incident management tools are being deployed by IT teams as a standard response to incidents.
However, for this to be effective, IT teams need to plan and prepare for the inevitable incident that might arise in the future. And, in the event of the occurrence of an incident, an alert signal shouldn’t be ignored and appropriate individuals should be notified.
The effectiveness of response efforts should be monitored and measured by IT teams to identify critical improvement areas after an incident. Automation of the component involved in the response process will allow synergy across the board and reduce the average resolve time for incidents.
To cater to the broad variety of possible events encompassing the term “incident”, a large range of operations is being deployed by incident management systems. Here are a few examples.
- • Escalations – This term might mean different things to different people, but it all boils down to delegating responsibility for an occurrence to another person. This could include sending an issue to a more experienced team (or a third-party supplier), modifying the incident’s priority (typically upwards), or amending the Incident and warning personnel if the resolution is likely to be delayed.
- • Internal teams — Thorough training of IT teams is necessary to improve the speed and effectiveness at which events are taken care of. Well-structured incident management systems ensure coordination among the internal teams which promotes to development of a clear strategy for dealing with any incident.
- • Virtual incident “situation rooms” and communications — One of the newly introduced functions of an incident management system in the ITIL v4 framework is the utilization of a virtual “situation room” for an incident. Invitation of the appropriate attendees, monitoring of actions and tasks, providing an accurate communication history, and exchanging of any relevant collateral and material is the sole responsibility of the system.
- • Communications with third parties – Most incident management operations require consistent communication between third parties and the IT team. The ability to close and handle all these communication gaps can be achieved through a robust event management system that ensures all wires are open during key periods.
- • Relationship with status pages – There is an increasing form of dependency by IT departments on status pages to communicate planned maintenance, system metrics and statuses, and outages to workers, users, and customers. However, when it comes to incident management, these status pages be used to alert the public about the occurrence of an incident.
Q94. Explain Capacity Management’s main objective and mention its sub-processes.
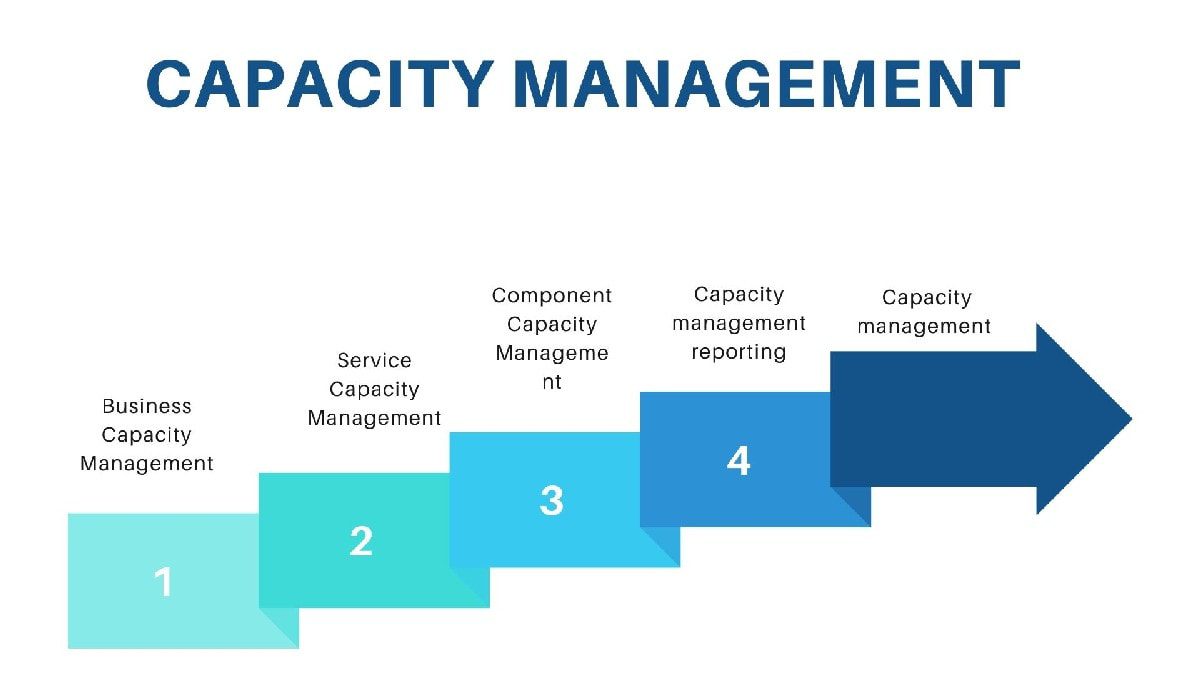
The capacity management process helps organizations to accurately determine the size of their IT services and ensures it meets the agreed service level cost-effectively. Three sub-processes make up capacity management:
Component Capacity Management
The main focus in this sub-process is on the technology, for example, databases, phones, and hard disks that facilitate the capacity and performance of IT services. Organizations need to understand the relationship between these components and their contribution to service performance.
The major difference between component capacity management and service capacity management is; the former predicts, controls, and manages individual component capacity and performance while the latter is focused on the service as a whole.
Component capacity management’s goal is to decrease the overall service downtime through the process of managing, controlling, and predicting present and future service performances.
Service Capacity Management
The service capacity management process is mainly concerned with the service’s operation. Here, the focus is on the service and not on the components as in the component capacity management.
This sub-process ensures that the delivered service meets the expected service-level requirements throughout its entire lifecycle. An excellent example of the application of the process is monitoring, managing, and predicting the smooth start and running of a ticketing system.
Business Capacity Management
The transition of business needs into IT service requirements is carried out by the business capacity management process. This sub-process is concerned with the service strategy and design stage. It also involves data analysis of the market before the IT service is launched to ensure the stability of the demand.
Business capacity management works alongside the demand management process to match the company’s demands with the services provided. While the other sub-processes focus on ensuring services fulfill the agreed-level of service requirements, business capacity management is concerned with ensuring that the service-level targets meet business needs and goals.
Effective implementation of this sub-process requires organizations to have an in-depth understanding of their SLAs and business requirements.
Q95. What is the importance of an information security policy?
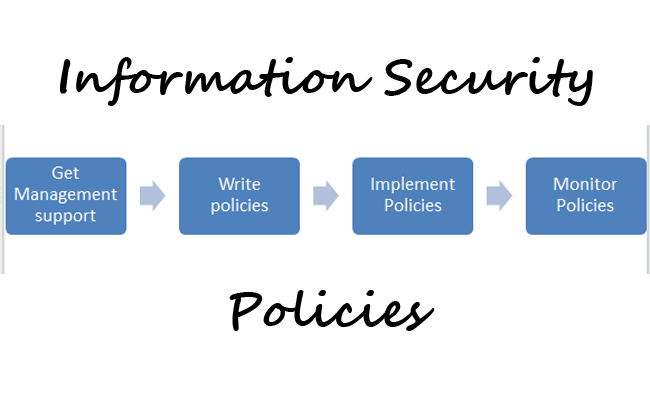
When establishing an organizational information security policy, the purpose is to provide meaningful direction and value to the organization’s employees in terms of security. IT security policies are intended to address security risks and execute measures to mitigate IT security vulnerabilities, as well as to specify how to recover from a network incursion.
Employees are also given recommendations on what they should and should not do as a result of the policies. The following are some of the most important reasons why your company should have IT security policies:
• IT security policies define what is expected of an organization’s employees in terms of security; • IT security policies reflect the management’s mindset and risk appetite regards the security of the company’s information and data
• The policies in an IT security policy serve as a foundation on which a defense system can be built against internal and external threats to the organization.
Q96. List the work-around recovery options.
The following are the possible workaround/recovery options:
• Do nothing – Popular in the past since it is free! It’s a high-risk technique these days, and it’s only appropriate if there’s no way to recover from a system failure. I can’t think of a system that is so easily replaceable, but they might exist!
• Manual Workarounds – Wherever appropriate and possible, manual workarounds can be an effective temporary measure until the IT Service is restored. Individual business units must determine whether this is possible. As IT becomes more integrated into the corporate infrastructure, manual solutions become less viable, as administrative cost rises and catching up becomes difficult.
• Reciprocal Arrangements – When the IT burden was largely batch processing, this was an effective contingency alternative. It is becoming increasingly less viable in today’s more complicated surroundings. Some reciprocal arrangements, such as the off-site storage of backups and other essential information, may provide some benefits.
• Gradual Recovery/Cold Standby – This is for enterprises that do not require immediate restoration of business processes. They can function without part or all of their IT facilities for at least 72 hours, if not longer. This is typically provided by vacant server rooms with electricity, network cabling, and external communications connections. This is then made available to an organization in the event of a disaster so that it can install its computer equipment.
This type of service is usually offered by specialized service providers, with whom businesses negotiate contracts. It is critical to specify where you are in the recovery process in the contract; for example, if several organizations request recovery at the same time, there may be inadequate resources to accommodate all of them, and it may become first-come, first-serve.
• Intermediate Recovery/Warm Standby – This is for enterprises that need to recover essential systems and services in 24 to 72 hours. The most popular method is to use third-party recovery providers, who distribute these to a small number of users, dividing the expense.
Operational, system management and technical support are frequently included in these facilities. The expenses for this type of recovery depend on two main factors; the time limit for the restoration of the services and the facilities needed.
• Immediate Recovery/Hot Standby – This restores key systems and services as soon as possible. It’s usually a more comprehensive version of Intermediate Recovery, and it’s usually provided by a third-party recovery company.
During the first 24 hours after a service disruption, for example, Immediate Recovery is accompanied by the recovery of other essential business and support areas. For even shorter timescales, having a distributed IT infrastructure and physically geographically replicating essential systems and data could be a solution for those enterprises who require it.
Q97. How is a Known Error recognized?
The problem management process is typically responsible for identifying Known Errors, but they can also be proposed by other Service Management disciplines, such as Incident Management, or by suppliers.
Q98. Who protects and maintains the Known Error database?

The Problem Manager.
The problem manager is an important member of an organization’s IT Service Management (ITSM) team. Their major goal is to prevent incidents from occurring as well as to reduce the severity of those that cannot be avoided.
The problem manager identifies, prioritizes, and allocates responsibility for problems before leading them through the complete solution process. Creating and administering a knowledge base to keep information about known errors and workarounds for use by the service desk and self-help portals is an important component of the job.
The day-to-day activities of a problem manager are frequently misunderstood. The problem manager isn’t in charge of resolving issues. The problem manager is in charge of evaluating event trends, recognizing repeat incidents, and determining where problem-solving efforts would provide the most return on investment for the company.
The problem manager requires various resources to offer diagnostic support, skills, and knowledge throughout the entire organization. Some of the responsibilities of a problem manager include:
• Coordination – The problem manager plays a major role in coordinating all problem diagnostic and resolution processes. He/she must have an accurate measure of the organization’s skillsets and knowledge to determine the most cost-effective solution to deploy toward resolving a problem.
• Communication – The problem manager is required to frequently update the various stakeholders about the progress recorded in the problem queue.
• Facilitation – Any team created by an organization to resolve a major incident should have a problem manager at its center. The problem manager helps in facilitating the data collection and analysis process. This guarantees that a long-term solution is studied concurrently with the incident team’s efforts to fix the immediate damage.
Q99. What is the Configuration baseline?
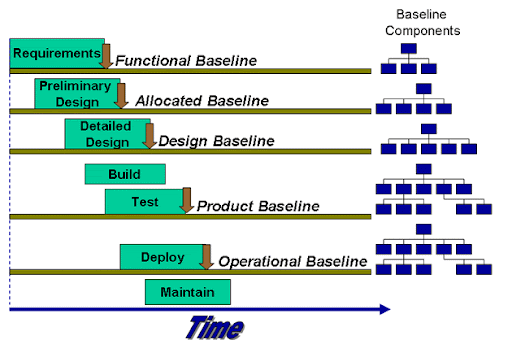
A configuration baseline is a reference point for a configuration that has been explicitly agreed upon and is being managed as part of the change management process. A company that provides IT services will offer a variety of services. All assets and services must be operational and follow one another to provide successful and high-quality service delivery to clients.
The configuration baseline can be used as a foundation for future builds, releases, and adjustments because it relates to the working condition of numerous configuration item releases and versions.
Let’s pretend the IT service provider improved several services at the same time. Some service management issues arose as a result of the upgrade. If the IT service provider has a configuration baseline from before the issues began, each configuration item can be restored to its original condition to resolve the issue.
Q100. What is Financial Management?
One of the Service Strategy stage procedures, Financial Management, is critical. It’s largely in charge of the following:
Budgeting
This procedure determines how much money an organization will make and how much money it will spend. Planning is done regularly (usually once a year). Planning is vital because it reduces the chance of future overspending.
Every month, the same technique is used to keep track of income and expenses. This means that monthly income and expenses will be tracked and compared to monies that have been budgeted (i.e., set aside). Measures can be done based on this information to execute corrections that will keep the budget on track.
Accounting
This procedure allows an IT company to keep track of how its money is spent. This is especially true when it comes to identifying costs by client, service, or activity. Accounting, for example, will respond to the query, “How much does e-mail service (per mailbox) cost?”
The response is important to someone who pays the bill (internal or external client). IT financial management must know which cost-item e-mail service is built to answer such an inquiry (e.g., hardware, software, people, etc.).
An efficient accounting process improves IT service offerings and identifies cost-cutting opportunities (i.e., financial efficiency). Accounting employs several cost components, including:
• Capital Costs (or capital expenditure – CAPEX): The cost of purchasing a financial item, such as a server.
• Operational Costs (or operational expenditure – OPEX): Expenses incurred in providing services, such as electricity bills, salaries, etc. CAPEX and OPEX can be controlled depending on the (financial) strategy of the company. One example is cloud-based services.
By adopting cloud services instead of building their own data center infrastructure, an organization can transfer capital expenditure (spending on their own data center equipment) to operational expenditure (paying a monthly charge for the resources they need).
• Direct Costs: Costs that can be allocated directly to a specific service or consumer, such as the purchase of a server that will only be used for one service.
• Indirect Costs: Costs that cannot be immediately assigned to a specific service or client, such as a software license for a server that serves multiple customers or runs multiple apps.
• Fixed Costs: Costs that do not fluctuate with the use of IT services or overtime, such as a yearly lease contract.
• Variable Costs: Costs that change over time depending on how much of a service is used, such as energy used to run servers.
Charging
Charging is the process of requiring payment for services rendered. Accounting procedures and systems must exist and be set up before charging may take place. It makes a difference whether the company is an internal service provider or whether its main business is serving external customers.
It is not necessary to bill for services when an IT organization is an internal service provider (Type I and Type II organizations according to ITIL). Occasionally, such IT groups do nothing but allocate expenditures. If an IT business offers its services to external consumers (Type III organization), it will almost definitely generate revenue by issuing bills for those services.
That concludes our list of top 100 ITIL interview questions and their answers, I hope you’ll find this list helpful when preparing for your next ITIL interview. While there’s no 100% guarantee that you’ll be asked some of these questions, it can help you guide your preparation and would come in handy during your interview.
Don’t limit to preparation to this article, you can also research online for as many as possible questions so as not to leave any stone unturned.
In addition, below are some interview tips that can help you leave a big impression on your interviewer making them more likely to hire you for the job.
Tips To Know Before The Interview

While preparing for your next interview, do the following to boost your chance of success:
1. Conduct an investigation about the background of the company, and if possible, the interviewers before the interview. The findings can improve your confidence and chances of success in the interview. You can make use of the company’s current news releases, social media posts, and website as an excellent source to identify the company’s aims and how you can fit in.
2. Practice your responses to both professional and general questions. For example, typical questions like “How can you help our company?”, and technical ones which have been answered above in this article. The goal is to be able to confidently and quickly answer the questions professionally while communicating to the interviewer what value you can offer to the organization and why they should pick you above others.
3. Review the job description to ensure you meet the criteria of the position you are applying for. Identify the specific skills that the employer is looking for and highlight the criteria that you meet using your previous work profile as an example.
4. Ask a friend to help you practice interview questions. This practice is an excellent preparation technique aimed at giving you a confidence boost and readying you ahead of the interview. This method simulates the interview environment, answers the questions out loud to make the interviewer-interviewee experience more realistic. Do this at least 3-5 times before the interview.
5. Prepare your reference list ahead of the interview date. Interviewers may request your list of references before or after the interview. You should have one ahead in case you ask to submit one impromptu, this would help speed up this stage so you can advance to the hiring process.
6. Come along with details of your past working experience. The interviewers would most likely ask questions about your previous experience in the role you are applying for. You should consider your experience, tasks, and success that fits into the job description profile that your employer wants.
7. Don’t plan to be only at the receiving end of the question, prepare intelligent questions for your interviewer about the job you are interviewing for. While most interviewers don’t, employers expect you to ask questions about the company, the position you are applying for, and job demands. Asking related questions would let your potential employer know that you are genuinely considering working with them. Examples of questions you might want to ask your interviewers include:
• What are the expected daily duties for this position?
• In case I was in this position, how will my performance be evaluated? How often would the evaluation process be done?
How would you characterize someone who would be successful in this position?
• With which departments does this team collaborate regularly?
• How do these departments usually work together?
• What does that procedure entail?
Tips to Note During The Interview

On the day of your interview, you can ensure everything goes perfectly and ace the interview by taking into consideration these few tips.
1. Dress like an employee. You don’t want to show up in your interview in something you’ll wear to a nightclub. Communication with a worker in the organization you’re is applying for to inquire about the workplace dress code and dress accordingly. In case you don’t know anyone, conduct some research about the company to find out what’s proper.
2. Come at least 10 minutes early to the interview. You can map out the route you will take ahead of the interview date. A trial run might give you an idea of how long the journey would take so you can determine your take-off time. Make contingency plans if you’ll be using public transit to cater for closures or delays.
3. Leave a lasting impression. Stand out from the crowd. Dress neatly; your shoes are shinning, your nails are tidy, and your clothes are free from stains, holes, loose threads, and pet hair. Don’t forget to always smile and maintain a confident demeanor throughout the interview process.
4. Be nice to everyone you come into contact with. By this, I mean the security, font-desk personnel, parking lot attendants, as well as drivers. Treat everyone as if they’re the interview if you’re meeting them for the first time. Your prospective employer might decide to seek their opinion concerning your conduct from them and a negative response can mar your chances of getting the job.
5. Maintain proper body language and etiquette. Your assessment for the interview starts the moment you walk into the establishment, so use approachable and confident body language. Maintain a good working and sitting posture; with your shoulders back, stand or sit tall. If you’re nervous before the interview, take a deep breath and exhale slowly to help calm you down and give you a confidence boost.
Never initiate a handshake with an interviewer, make sure it’s the interviewer that is extending their hand first. A decent handshake should be forceful but not crushing to the fingers of the other person. Also, maintain eye contact with the interviewer and don’t forget to smile.
6. Be your true self. Most often time, the interviewers are people you’ll later be working with if you’re employed. Prove your optimism and sincerity to them, this might help them relate to you more easily.
7. Be honest in all your responses. Don’t exaggerate your achievements or qualifications, instead concentrate on strong points, past experiences, and how you’re fit for the position. Interviewers find honesty admirable and refreshing, don’t put yourself in an awkward position by getting caught in a lie.
8. Be swift, concise yet precise with your answers. There is limited time for the interview process, so be prepared to answer the questions without rambling or mincing words. An excellent piece of advice is to prepare your answer ahead of time.
9. Avoid bad-mouthing your previous workplace or boss. This doesn’t always reflect well on you because organizations are looking for problem solvers that can work through adversity. Don’t express your dissatisfaction about your current or previous employment but rather talk about the good experience and lessons learned during your time working there.
Tips To Apply After The Interview
After completing the interview, here are some follow-up actions you can take to improve the chances of getting employed.
1. Ask your interviewer about your options for the next steps. At the end of the interview, you should ask the interviewer about what is expected following the interview. This could mean an assignment, a list of references, another interview, a follow-up email with the results of your interview, or further requirements.
2. Following the interview, write a personalized thank you letter to each of the interviewers. You can get their personal information by asking for their business cards during the interview process.
There is no perfect time to send the follow-up message, but ensure you send it a few hours after the interview. For example, if the interview was in the morning, then you should send the message the same day. By making use of the notes you took during the interviews process, you can easily distinguish your message from the other interviewees.